Paradis artificiels ✨
Carnet de notes d'un traducteur passionné d'IA
Dernière modification : 21/01/2026 à 09:55:44
Contact : sebington arobase gémel point com
20-01-2026
Petite annecdote symptomatique de cette folie agentique dans laquelle nous baignons. Ce matin je veux récupérer une image par seconde d'une vidéo pour un projet. Je sais que je l'ai déjà fait, que c'était facile, et que j'avais probablement utilisé ffmpeg. Mais je ne me souviens pas de la méthode. Je fais des recherches dans mes tablettes, rien. Je me dis, demandons à Claude, il va me chier un truc en deux secondes.
Je prompte Claude et par curiosité ne mentionne pas ffmpeg ("Write a Python script that will do a video frame freeze every second"). Claude me pond un script d'une soixantaine de lignes faisant appel à une bibliothèque nommée opencv-python. Le script ne fonctionne pas, je demande à pi de le réparer, rien à faire. Je lui demande alors de "refactor" le code en utilisant ffmpeg, pi s'exécute puis vérifie dans la foulée si ffmpeg est installé sur le système (WSL), et comme ce n'est pas le cas, s'arrête.
Par paresse, je demande alors à pi d'installer ffmpeg. Pi essaie, mais est empêché par l'absence de mot de passe "sudo". Avant que j'aie le temps de dire ouf, il a trouvé une solution alternative : il télécharge une version "statique" de ffmpeg ("Let me try downloading a static ffmpeg binary that doesn't require installation"), configure le script en conséquence et ça fonctionne : je récupère une image par seconde de vidéo.
Ce soir je vérifie. Des recherches plus poussées révèlent que Claude il y a un an m'avait donné une solution mille fois plus élégante sous la forme du oneliner suivant : ffmpeg -i video.mp4 -vf fps=1 slide_%d.jpg. En une quarantaine de caractères espaces compris, ffmpeg en mode console réglait le problème en une fraction de seconde. Le prompt était simplement : "I want to extract slides from a YouTube conference video. What are my options?".
Moralité #1 : on le savait déjà mais oui, le prompt conditionne énormément la réponse. Le prompt de ce matin manquait de clarté tout en étant trop directif. Le prompt d'il y a un an était plus neutre, plus ouvert et plus précis.
Moralité #2 : évitons de lancer certaines commandes non-essentielles au sein d'un outil d'agentic coding. Leur résultat est en effet ajouté au contexte de la conversation et cela peut engendrer une consommation parfois inutile de tokens. Mieux vaut exécuter ces commandes dans autre instance de terminal. Et s'il faut absolument que le LLM "voie" le résultat, préférons le copier-coller "manuel" d'un terminal à l'autre.
19-01-2026
"Many of us got hit by the agent coding addiction. It feels good, we barely sleep, we build amazing things. Every once in a while that interaction involves other humans, and all of a sudden we get a reality check that maybe we overdid it. The most obvious example of this is the massive degradation of quality of issue reports and pull requests. As a maintainer many PRs now look like an insult to one’s time, but when one pushes back, the other person does not see what they did wrong. They thought they helped and contributed and get agitated when you close it down."
-- Armin Ronacher - Agent Psychosis: Are We Going Insane?
------
J'essaie de faire du web scraping avec pi en utilisant une "skill" (browser-tools) créée par l'auteur de l'outil. La skill en question s'appuie sur le Chrome DevTools Protocol pour fonctionner. Je me rends bientôt compte qu'il est possible d'installer Chrome ou Chromium sur WSL, et qu'ils peuvent fonctionner en mode "headless". On peut alors lancer des commandes du genre :
# Basic headless mode
chromium-browser --headless --disable-gpu --dump-dom https://example.com# Take a screenshot
chromium-browser --headless --disable-gpu --screenshot=/tmp/screenshot.png https://example.com# Generate a PDF
chromium-browser --headless --disable-gpu --print-to-pdf=/tmp/output.pdf https://example.comLorsque je fais un test, big-pickle m'indique que le script browser-start.js n'est pas compatible avec Linux car il contient du code spécifique à MacOS. Je demande à l'outil de réparer le problème, ce qu'il fait. Ensuite la skill fonctionne correctement et récupère les infos demandées. Enfin, je demande à pi/big-pickle d'écrire une "GitHub Issue" signalant le problème au développeur. Par précaution je consulte les Pull Requests en cours et constate que quelqu'un a déjà signalé le problème et proposé une solution. Je n'ai donc rien à faire mais suis content de constater que mon diagnostic était le bon.
18-01-2026
Mon outil voice2prompt fonctionne à nouveau. La deuxième partie de la session de "refactoring" s'est bien terminée. Le modèle principalement utilisé était google-antigravity/gemini-3-pro-high. Une fois le free tier épuisé, je suis passé à opencode/glm-4.7-free, puis à opencode/big-pickle. Tous les deux m'ont laissé tombé après quelques minutes, mais l'essentiel du travail avait été fait et l'outil était fonctionnel. J'ai supprimé les fichiers temporaires et ai fait un /init avec Claude Code pour recréer un fichier CLAUDE.md "propre" et mettre à jour le fichier README.md de GitHub (que j'ai modifié à la main ensuite).
L'outil se comporte maintenant comme les autres outils du même genre. Un modèle de Whisper est automatiquement téléchargé si pas déjà présent sur la machine. On enregistre sa voix en restant appuyé sur une touche du clavier et quand on lâche la touche, la transcription s'effectue et le texte est collé automatiquement là où se trouve le curseur. L'ensemble est constitué de 3 fichiers : deux scripts en Python et un script en Bash.
Mise en ligne de la nouvelle version sur GitHub. Claude Code me propose de gérer les commandes git à ma place mais je préfère m'astreindre à les passer manuellement pour mieux comprendre. Finalement on peut s'en sortir avec un nombre réduit de commandes. Voici celles que j'ai utilisées jusqu'à maintenant (en ordre alphabétique) :
git add .
git clone
git commit
git config
git diff
git init
git log --oneline
git push
git remote add origin
git rm --cached fichier.md
git status17-01-2026
Sortie il y a 3 jours de Pocket TTS, un modèle text-to-speech de seulement 236_Mo qui peut donc fonctionner en local et semble donner de très bons résultats. Kyutai est un laboratoire français de recherche ouverte en intelligence artificielle. En consultant leur site, je constate qu'ils ont également développé un modèle de speech-to-text comparable à Whisper et surtout Unmute.sh, un outil qui permet de dialoguer en direct avec un modèle spécialement prompté pour adopter un comportement ou incarner un personnage défini. Je discute un moment avec le Général de Gaulle, puis avec un personnage féminin qui parle français avec un délicieux accent anglais et m'explique comment Unmute a été conçu (apparemment avec un modèle de Mistral finetuné). En tout cas l'interface est superbe et ça marche du feu de Dieu.
Le problème des MCP qui bouffent le contexte de Claude Code aurait été résolu par Anthropic, si l'on en croit cette vidéo.
16-01-2026
Sortie de translategemma. J'installe le modèle 4B sur Ollama et effectue quelques tests rapides. Le résultat semble assez correct pour un modèle de cette taille. Il faudrait comparer avec d'autres modèles généralistes de taille similaire, puisque, sauf erreur, la traduction est une "capacité émergente" de presque tous les LLM.
Je passe un certain temps à passer en revue les distributions Linux qui peuvent se charger entièrement en mémoire (fonctionnalité "TO_RAM"). C'est une obsession que j'ai depuis des années et de temps en temps je fais une petite crise/rechute. J'en retrouve pas mal (Slax, SliTaz, Porteus...) déjà utilisées maintes fois mais rien de très nouveau ou décisif. Ce chargement en mémoire est également possible avec certaines "grosses" distributions. Je crois que l'ISO de CachyOS se charge entièrement en mémoire quand on boote à partir d'une clé USB. J'aime bien cette idée d'un OS volatile et léger, même si cela implique aussi de grosses contraintes. A suivre.
Ce soir je tente l'implémentation du plan de Claude Code pour voice2prompt. En gros il s'agit de rendre l'installation et l'utilisation plus simples et fluides. Je démarre avec Gemini 3 et poursuit avec Big Pickle. Session très difficile car Wayland est vraiment délicat à gérer au niveau des autorisations. Par moments pi explore les entrailles d'Ubuntu pour tenter de résoudre les problèmes. L'appli se lance et répond aux évènements clavier mais impossible de capter ma voix et encore moins de la transcrire. Il faut que je regarde le code et que j'isole les différents modules pour savoir où ça coince. En matière de développement informatique, je crois que l'humain a encore de beaux jours devant lui.
15-01-2026
Je fais une session inédite et excitante sur pi avec claude-sonnet-4-5. Je lui demande de se connecter à l'API de models.dev (https://models.dev/api.json) pour faire quelques analyses statistiques. Pi se débrouille avec Curl pour récupérer le fichier JSON et l'aventure commence. Je pose mes questions sur les données directement dans pi, qui utilise les outils adéquats pour me répondre (au début du Bash très sophistiqué). Je lui conseille d'utiliser uv, Python et Pandas pour de meilleurs résultats. Il faut être attentif à ce qu'il trouve quand il filtre les données mais globalement ça marche plutôt bien. Je lui pose des questions de plus en plus complexes qui demandent une analyse croisée et il fait du super boulot. Vraiment génial comme outil car tellement polyvalent.
Je refais refais le même exercice avec Mistral-Vibe et Gemini CLI, en utilisant exactement les mêmes prompts (au moins au début). Tous les deux s'en sortent honorablement, Vibe étant beaucoup plus réactif que Gemini. Olivier fait la même chose avec Claude Code. A première vue les résultats semblent diverger et demanderaient une analyse comparative plus poussée. A noter que Claude Code et Gemini CLI "nettoient derrière eux" et suppriment la plupart des fichiers temporaires utilisés pour générer les statistiques, tandis que pi et Vibe laissent tout le bazar dans leurs répertoires de travail, qui à la fin de la session font 109 et 114 Mo respectivement.
------
Ce soir je visionne la dernière vidéo de Matt Pocock, qui pour la première fois me déçoit car elle promet sans tenir, ce qui est typique du comportement de certains youtubeurs avides de clics et d'auto-promotion. Toute une vidéo pour deux malheureuses lignes qui sont sensées révolutionner la manière avec laquelle Claude Code va planifier votre futur projet. Du vent.
Bon, la vidéo de Pocock m'a tout de même donné envie de tester le "mode plan" de Claude Code. Je l'utilise pour planifier la suite des améliorations prévues pour mon assistant vocal, ce qui me revient à $0.86. A la fin de la phase de planification Claude me propose de visualiser le plan dans VSCode en faisant Ctrl + G (ou qq ch comme ça) et quand je reviens dans le terminal, Claude Code bugue grave et "freeze" au point que je dois faire un double Ctrl + C sauvage pour sortir.
13-01-2026
Bien avancé sur mon assistant vocal. Ajout d'icônes dans la barre des tâches en haut. Pas mal d'essais avant d'obtenir quelque chose qui fonctionne à peu près. Un carré vert s'affiche quand le processus tourne en arrière plan et un carré rouge clignotant remplace le carré vert quand ça enregistre et ça transcrit. C'est le script en Python qui construit l'icône à la volée au lieu d'utiliser une image par exemple. Utilisation de Git pour récupérer une version antérieure de mon code si le LLM s'emballe.
J'ai fait appel à GLM 4.6. Modèle très réactif et pertinent, vraiment un plaisir à utiliser. Pour l'instant mon outil reste un peu délicat à manipuler mais il fait le taf. Je refais une session avec Gemini qui en remet une couche. Il trouve des améliorations possibles au niveau du "Clipboard Manager" qui est maintenant compatible avec Wayland ET X11. Je fais un git push sur GitHub, mais n'ai plus la force de m'occuper du fichier README.md ce soir. C'est de la folie ces outils.😵
11-01-2026
Journée maussadissime comme seul(e) Brest sait en produire 🌧️🌧️🌧️
J'organise les dossiers des skills que je compte utiliser avec pi. Elles proviennent de 3 sources : Mario Zechner, Armin Ronacher et Claude. Puis je demande à pi de créer une skill à partir d'un script en Python qui fait une recherche sur le web avec DuckDuckGo et en fait un petit résumé. Pi s'exécute avec Big Pickle et Minimax et me crée une nouvelle skill : web-search-summarize, que je teste et qui fonctionne.
Cet après-midi, visio avec Olivier où nous échangeons pendant 2h sur nos projets respectifs et l'évolution des outils de codage agentique.🤓
Ce soir comme prévu je modifie mon script "voice assistant daemon/groq" pour le faire fonctionner en local avec pywhispercpp. Minimax s'en occupe en deux temps trois mouvements. Je teste avec un modèle multilingue et non anglais-seul : à ma surprise quand je parle en français Whisper traduit ce que je dis et me livre la transcription en anglais. Je fais plusieurs essais, rien à faire. C'est peut-être le modèle qui a été mal étiqueté. On verra ça plus tard.
10-01-2026
Je teste pi avec le modèle opencode/big-pickle. J'essaie de modifier le script de départ de mon assistant vocal, qui fonctionnait avec whisper.cpp et qui avait nécessité de compiler whisper.cpp depuis la source, ce qui rendait le projet très fouilli. Je propose à pi d'utiliser pywhispercpp à la place.
Big-pickle démarre au quart de tour et s'attaque au problème sans traîner. Je suis impressionné. Suite à une erreur, il propose d'utiliser arecord un outil natif de Python à la place de pyaudio.
"I've successfully converted the script to use arecord (Linux command-line tool) instead of pyaudio/sounddevice. This eliminates the PortAudio dependency issue."
Je teste le script avec ce modèle de whisper de 148 Mo et ça marche nickel, avec une vitesse comparable à celle de Groq.
Note : Olivier découvre que derrière l'appellation "Big Pickle" se cache le modèle GLM 4.6 de z.ai.
09-01-2026
J'aimerais bien utiliser l'API payante de Groq pour la rapidité de l'inférence, mais je trouve leur sélection de modèles assez bizarre, assez pauvre en termes d'agentic coding, et à chaque fois ça me dissuade de sauter le pas. J'en parle à ChatGPT, qui me répond que le produit phare de Groq est maintenant Compound, un système d'IA agentique spécialement conçu qui intègre l'utilisation d'outils (recherche sur le Web, exécution de code, automatisation du navigateur, etc.) dans un seul appel API. Pas sûr de comprendre vraiment comment ça marche. En plus, le tarif pour 1M de tokens de Compound ou Compound Mini est bizarrement absent de leur tableau.
08-01-2026
Remarques sur les différents outils d'agentic coding que je teste :
-OpenCode : ne montre pas assez ce qu'il fait quand il travaille. C'est assez frustrant de ne pas savoir où il en est. En revanche OpenCode propose toujours quelques modèles "gratuits" (Big Pickle, MiniMax M2.1 ou GLM 4.7).
-Mistral Vibe : marche bien, assez réactif une fois qu'on l'a mis en mode YOLO sinon il s'arrête toutes les deux secondes. Documentation très minimale et pas à jour. Bugs. L'accès au free tier peut être interrompu à tout moment.
-Gemini CLI : Gratuit mais parfois assez peu réactif, voire lent. Interface et affichage au top je trouve. Bon pour analyser et débugguer. Fiable. Fais parfois des merveilles.
- Pi : très fluide, rapide et facile à prendre en main. Peut entre autre se connecter aux modèles free tier d'Antigravity. Possibilité de générer un fichier html de la session avec une interface de recherche très bien pensée pour retrouver le contenu de la session dans ses moindres détails. Les commandes /tree et /branch sont très utiles pour revenir en arrière en cas de problème.
- Claude Code : pas grand chose à lui reprocher sauf peut-être son côté un peu usine à gaz (tellement de fonctionnalités qu'on s'y perd). Mais c'est probablement le meilleur outil en ce moment.
------
Depuis hier je retravaille sur l'assistant vocal commencé le 4. Travail acharné et approches multiples : whisper.cpp, vosk, whisper/groq. Script qui se limite à une seule instance de terminal puis processus (daemon) qui tourne en arrière plan (incontournable). Script en bash déclenchable avec raccourci, demandes de conseils à ChatGPT pour l'approche et la planification à cause de Wayland, multiples outils CLI (ils y sont tous passés). C'est Gemini CLI qui finit par tout décoincer.
L'outil lance un processus via un script en Python qui attend que l'utilisateur tape une touche sur le clavier. La première frappe de la touche déclenche l'enregistrement de la voix et la seconde arrête l'enregistrement et envoie les données audio à Whisper via l'API de Groq. Groq renvoie la transcription, qui est stockée dans le "presse-papier" de la machine. L'utilisateur fait Ctrl+V pour coller le texte à l'endroit voulu. J'ai essayé de faire en sorte que le collage se fasse automatiquement mais pour l'instant rien à faire, Wayland est verrouillé de tous les côtés.
Ce genre de projet est difficile à débugguer car il fait appel à des éléments multimédia. Quand ça ne marche pas il faut décrire précisément ce qui ne va pas. L'outil ne peux pas se contenter de lancer le script et d'analyser la sortie puisqu'il y a un élément humain au beau milieu : la voix de l'utilisateur. Cela demande de prompter de façon ultra précise, mais ça finit par payer.
06-01-2026
Je continue ma quête du Graal sous la forme d'un outil performant de correction-révision par IA. J'installe les Claude Skills sur pi et demande à Gemini-3-pro-high et à Sonnet-4-5 de réviser un document Word en utilisant la skill "docx". J'adopte donc l'approche : "ne fabrique pas un outil, tu es l'outil".
Prompt : "Use the docx skill to perform a professional revision, copy-editing and proofreading of @file_original.docx. Output a .docx file in track change."
Gemini bosse pendant 5 bonnes minutes et produit un document en mode suivi des modifications assez correct, sans être parfait. Je réitère avec Sonnet-4-5 mais grosse déception, l'opération se solde par un échec alors que je pensais que Sonnet ferait mieux que Gemini. Le document n'a subi quasiment aucune modification. La quête continue mais je sens que je tourne en rond et que le fait de vouloir absolument un document Word en sortie est très limitant.
------
Github a ajouté un chatbot sur sa page d'accueil (GPT5-mini par défaut). Mes premières questions concernant des statistiques portant sur des dépôts Github ne rencontrent pas un franc succès. Le chatbot me répond qu'il n'a pas accès à certaines données. Ma troisième tentative porte sur un outil de voice-to-text et génère une réponse intéressante, qui disparaît au bout de quelques minutes. Pas encore très au point leur truc.
05-01-2026
Je continue d'utiliser pi pour coder. Les versions de pi sur Github se succèdent et l'outil me semble performant et fluide. Impression d'être à la pointe de ce qui se fait en agentic coding, ce qui est grisant. Je m'en sert pour développer une appli sur Linux qui gère mes centaines de fichiers GPX. Gemini la décrit comme suit : "A desktop GUI application built with PyQt6 for managing, viewing, and analyzing GPX (GPS Exchange Format) files." Rien de révolutionnaire comme appli mais une fois la base construite et à peu près fonctionnelle, je peux demander toutes les fonctionnalités ou améliorations que je souhaite et les teste dans la foulée. Le kiff intégral.
Hugging Face met en ligne un autre tuto intéressant sur smolagents, une de leurs bibliothèques Python.
Et pendant ce temps-là, les modèles chinois ne cessent de progresser.
04-01-2026
Je demande à pi de me fabriquer un assistant vocal pour dicter mes prompts dans le terminal d'Ubuntu. Je lui demande d'utiliser uv et whisper.cpp. L'opération prend une petite heure et est rendue compliquée par le fait que whisper.cpp ne propose plus de fichiers précompilés pour Linux. Il faut utiliser CMake et compiler soi-même. J'utilise exclusivement claude-sonnet-4-5 et grille du token à la pelle.
↑154 ↓32k R2.0M W99k $1.449 26.7%/200k (auto)A la fin du processus j'ai un outil (v1) qui fonctionne et qui se déclenche avec une touche du clavier. Seul souci (de taille) à régler : comment faire pour que l'outil fonctionne dans une autre instance de terminal que celle qui lui est dédiée ? J'y travaille quand je suis arrêté par Claude qui me notifie une erreur 429 "rate_limit_error". C'est assez barbant. Chose étrange, si je passe de pi à Claude Code, tout fonctionne et je n'ai plus l'erreur 429.
La suite est moins glorieuse. J'utilise tour à tour Claude Code, OpenCode et à nouveau pi sans parvenir à régler le problème. L'interruption de pi/sonnet alors qu'il semblait en si bon chemin semble avoir été fatale. Les combinaisons de touches ("hotkeys") ne fonctionnent pas, Sonnet incrimine Wayland et se perd dans des vérifications sans fin. Je vais devoir me contenter de la v1 pour l'instant.
Finalement Gemini me donne l'explication : c'est bien Wayland le coupable, Sonnet avait raison. "Wayland prioritizes security and isolation, which presents significant hurdles for "System Utility" apps. One of the key obstacles on Wayland is Input Isolation. Applications cannot "spy" on other windows. There is no simple API to detect a global hotkey press unless the app is currently focused." Ce n'est pas la première fois que j'ai des soucis à cause de Wayland.
03-01-2026
Je recommande chaudement la lecture de The year in LLMs de Simon Willison.
Un truc qui passionne les foules est la génération d'images. Quand ChatGPT a ajouté cette fonctionnalité en mars dernier, elle a suscité la création de 100 millions de comptes en une semaine, avec un pic d'un million atteint en seulement une heure. Un peu triste quand même.
Idem avec l'énorme succès de Nano Banana chez Google, sorti en août. Ce qui me rassure presque, c'est qu'Anthropic reste en retrait de ces "frivolités" (qui n'en sont pas vraiment, je le concède) pour se concentrer sur des produits fiables pour développeurs. Leur victoire à eux, c'est Claude Code et pas des images de petits chats en guimauve ronronnant sur Mars.
"Google’s biggest advantage lies under the hood. Almost every other AI lab trains with NVIDIA GPUs, which are sold at a margin that props up NVIDIA’s multi-trillion dollar valuation. Google use their own in-house hardware, TPUs, which they’ve demonstrated this year work exceptionally well for both training and inference of their models."
------
Je visionne ce tutoriel mis en ligne il y a quelques jours par Hugging Face, qui va clairement dans le sens d'une démocratisation du travail collaboratif sur Github. Je me dis qu'une telle vidéo appelant quasiment tout un chacun à réparer ou optimiser du code aurait été inconcevable il y a moins d'un an. C'est dire si les choses sont en train de changer.
02-01-2026
Je lis l'intégralité du billet de blog de Mario Zechner dont je parlais hier. Il explique sa philosophie minimaliste (j'adore) et la manière de développer son outil d'agentic coding customisé.
Malgré certains passages très techniques, ce billet est vraiment passionnant et me permet de mieux comprendre le fonctionnement, les avantages et les limites des outils comme Claude Code.
Mario insiste sur l'inutile complexité de certains de ces outils, qui se fait au détriment de la performance.
"Over the past few months, Claude Code has turned into a spaceship with 80% of functionality I have no use for. The system prompt and tools also change on every release, which breaks my workflows and changes model behavior. I hate that."
Il explique que le prompt "système" de pi est très court. Tout est fait pour ne pas surcharger inutilement le contexte du modèle.
"It turns out that all the frontier models have been RL-trained up the wazoo, so they inherently understand what a coding agent is. There does not appear to be a need for 10,000 tokens of system prompt. pi's system prompt and tool definitions together come in below 1000 tokens."
Concernant la sécurité et l'utilisation du mode "YOLO", il explique que la plupart des soit-disant mesures de sécurité des autres outils populaires sont de la poudre au yeux ("security theater").
"pi runs in full YOLO mode and assumes you know what you're doing. It has unrestricted access to your filesystem and can execute any command without permission checks or safety rails. No permission prompts for file operations or commands. No pre-checking of bash commands by Haiku for malicious content. Full filesystem access. Can execute any command with your user privileges.
If you look at the security measures in other coding agents, they're mostly security theater. As soon as your agent can write code and run code, it's pretty much game over."
Concernant d'autres fonctionalités comme les MCP, les processus lancés en arrière plan ("background bash") ou les "sub-agents", Zechner rejette tout en bloc par souci de simplicité et d'efficacité.
"Popular MCP servers like Playwright MCP (21 tools, 13.7k tokens) or Chrome DevTools MCP (26 tools, 18k tokens) dump their entire tool descriptions into your context on every session. That's 7-9% of your context window gone before you even start working. Many of these tools you'll never use in a given session."
Je continue d'apprivoiser pi. Je le fais fonctionner en local avec Ollama et Qwen2.5:7b. C'est bien sûr hyper lent (CPU-only) mais ça donne de bons résultats. J'installe les pi-skills proposées par Mario sur son Github. Au début ça ne marche pas, problème de configuration de npm que pi résoud en quelques secondes, puisqu'il a accès à toute la machine. Super pratique. Je teste une skill (transcription d'une vidéo YouTube de 5 minutes). Ça fonctionne du tonnerre et fait appel à Groq via un script en Bash. Hâte de continuer !
01-01-2026
Journée riche en découvertes. Encore Armin Ronacher. Hier je regarde sa dernière vidéo (à laquelle je ne comprends pas grand chose sur le moment) mais constate cependant que sa version de Claude Code affiche des infos en temps réel sur la session en cours (avec notamment le coût en dollars, la taille du contexte et le modèle utilisé) en bas de son terminal. Exemple :
↑94 ↓22k R783k W164k $1.178 22.2%/200k (auto) claude-sonnet-4-5Je demande à Armin s'il utilise un outil spécifique pour cela et il me répond que ce qu'il utilise dans la vidéo n'est pas Claude Code comme je le croyais mais un autre outil qui s'appelle pi. Je me dis que si Ronacher utilise ce truc, c'est que ça doit valoir le coup et je tente l'expérience.
Je l'installe et lance une session avec Sonnet-4-5. C'est comme Claude Code en plus direct, genre "on arrête de tourner autour du pot". Si on essaie de résumer : outil minimaliste, avec une philosophie assumée. Quatre "tools" de base : read, write, edit, bash. Détecte les clés API présentes sur la machine et affiche les modèles correspondants. Mode YOLO par défaut. L'outil peut "sortir" du répertoire qui lui a été assigné et aller voir autour. C'est d'ailleurs ce qu'il fait dès le départ en "lisant" Downloads/AGENTS.md, un fichier qui ne lui était pas destiné.
Autre fonctionnalité saillante, un mode d'auto-compactage de la fenêtre contextuelle activé par défaut. C'est super pratique, on n'est pas obligé de surveiller le contexte sans arrêt.
Ce qui est différent : par défaut pas de MCP (les Skills sont encouragées à la place), pas de "sub-agents", pas de "plan mode", pas de listes de tâches (built-in to-dos). Explications sur le blog du développeur.
Un truc super pratique : l'outil peut exporter nativement l'ensemble de la session en HTML, même si elle a été auto-compactée et que le début de la session n'est plus visible dans le terminal. Et le rendu du HTML est magnifique je trouve. Je suis conquis.
Cerise sur le gâteau : en cherchant le site de "pi", je tombe sur le blog d'Armin Ronacher, dont j'ignorais l'existence et que je conseille fortement. L'avant dernier billet, A year of vibes, est un récapitulatif de cette année 2025 complètement dingue avec l'agentic coding arrivant à maturité. Le dernier billet, Advent of Slop, a été écrit par Claude à la demande de Ronacher (prompt complet et "disclaimer" à la fin).
Enfin, une partie du blog est consacrée à des sujets plus sombres, avec une esthétique (nuages "programmés" en perpétuels mouvements) très réussie je trouve. Ce mec a du talent.
31-12-2025
Hier Karpathy désemparé. Aujourd'hui Ronacher enthousiaste.
"The puzzle is still there. What’s gone is the labor. I never enjoyed hitting keys, writing minimal repro cases with little insight, digging through debug logs, or trying to decipher some obscure AWS IAM permission error. That work wasn’t the puzzle for me. It was just friction, laborious and frustrating. The thinking remains; the hitting of the keys and the frustrating is what’s been removed."
-- Armin Ronacher - 29 décembre 2025
De manière complètement inattendue, Mistral-Vibe fonctionne à nouveau (gratuitement). Je l'ai juste mis à jour (v1.3.3). Vibe a tenté de développer une appli de gestion de fichier GPX avec electronjs mais à chaque tentative de lancement (npm run dev), ça échoue. Vibe a essayé de débuguer plusieurs fois mais sans succès. Je laisse tomber pour l'instant et retourne sur CC.
30-12-2025
"I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind."
-- Andrej Karpathy - 26 décembre 2025
29-12-2025
Découverte sur Ollama.com de functiongemma, "a specialized version of Google's Gemma 3 270M model fine-tuned explicitly for function calling". Je télécharge le modèle attiré par son poids plume (301 Mo) et le teste avec le script proposé dans la description, qui fonctionne mais ne fait pas grand chose (démo). Je donne le code à Claude et lui demande de me générer d'autres scripts plus intéressants. Claude me propose entre autre un script sensé servir de calculatrice requêtable en langage naturel. Le script fonctionne mais on sent les limites de functiongemma, qui échoue quand on lui demande de calculer l'aire d'un cercle par exemple. Je décide d'essayer d'autres modèles compatibles avec le "function calling" (Mistral, Llama3.2 et Qwen2.5). C'est avec Qwen2.5 (7b) que j'obtiens les meilleurs résultats. Rappelons que les calculs sont effectués par le script en Python, et que le modèle n'est là que pour "orchestrer" les choses.
28-12-2025
Pour démarrer mon appli de gestion de fichiers GPX, je tente une petite expérience. Je lance simultanément 3 outils d'agentic coding (OpenCode avec GML-4.7, Gemini CLI avec Gemini 3 et Claude Code avec Sonnet pour la planification et Haiku pour l'implémentation) dans 3 répertoires différents. Chaque répertoire contient exactement les mêmes instructions dans un fichier nommé AGENTS.md et quelques fichiers GPX pour tester.
Je demande avant tout aux outils de produire un plan d'action. Quand chaque outil a accompli cette tâche de planification, je leur dis de commencer à implémenter l'appli. Au bout d'un quart d'heure Gemini me propose une interface web complètement stérile avec de jolis logos mais rien de fonctionnel et OpenCode me montre une liste de fichiers GPX mais est incapable d'en afficher un sur une carte malgré mes multiples relances.
Seul Claude Code propose d'emblée une appli basique mais fonctionnelle, avec la liste des fichiers GPX à gauche, une carte (OpenStreetMap) au centre sur laquelle on visualise le premier fichier GPX de la liste et une colonne à droite avec le détail de chaque fichier. Je continue d'interagir avec Claude Code, qui non seulement répond avec pertinence à chacune de mes demandes, mais prend le temps de m'expliquer pourquoi l'implémentation de certaines fonctionnalités est conditionnée à certains impératifs comme par ex. le type de navigateur utilisé. J’apprends donc des choses tout en faisant et cela renforce le côté agréable de la session.
Il reste beaucoup de travail avant d'obtenir ce que je souhaite. Une appli comme celle-ci demande de nombreux ajustements tant sur le fond que la forme. Le fait que l'appli soit fonctionnelle dès le début de la session permet de tester chaque changement en temps réel. Je fais la navette entre la fenêtre du navigateur et celle du terminal. Le code en TypeScript, un langage que je ne maîtrise pas, reste abstrait et secondaire. Pour pallier à ce problème et visualiser le code en direct, on peut utiliser VSCode avec le Claude Code plugin ou bien Antigravity. Mais attention, les possibilités sont infinies et il n'y a toujours que 24 heures dans une journée.
27-12-2025
Je regarde à nouveau Deep Dive into LLMs like ChatGPT d'Andrej Karpathy, une vidéo qui devrait être traduite et rendue obligatoire au lycée et à l'université tellement elle explique bien la conception et le fonctionnement des grands modèles de langage (LLM) comme ChatGPT. Je télécharge les 3400+ commentaires de la vidéo avec youtube-comment-downloader et obtient un énorme fichier JSON que (sans trop y croire) je donne tel quel à Gemini avec le prompt suivant :
Can you extract interesting and constructive comments out of this json file, people asking questions for example, and thus discarding comments that just say 'thank you' or joke?
Voici le résultat.
------
J'essaie de mettre en application cette excellente idée de Simon Willison. Je décide d'utiliser Google Jules (que j'ai déjà utilisé une fois auparavant), avec le prompt suivant.
I plan to develop a web app that will be able to parse, display and run stats on hundreds of GPX files of walking/running and mostly cycling activities. Please advise on the features this app could propose and the technology used (e.g. JavaScript, TypeScript, npm, etc.) by exploring various codebases and draft a report.md file.
Tout se passe relativement bien malgré quelques maladresses de ma part. Jules finit par générer 2 fichiers et produit un Pull Request dans Github. Voici le résultat du processus.
------
David Louapre fait à nouveau parler de lui. Décidément !
26-12-2025
Je regarde la dernière vidéo d'Alex Finn sur les Claude Skills et une fois de plus je suis frappé par sa manière de parler. Tout (intonation, timbre, rythme, diction, débit...) fait penser à la manière de parler de Trump. Le fait-il exprès ? Pour en avoir le cœur net je me rends sur https://ytcomment.kmcat.uk/, colle le nom de la chaîne (https://www.youtube.com/@AlexFinnOfficial/) et fais une recherche avec "Trump" comme seul mot clé. Avalanche de résultats : 34 internautes se font exactement la même remarque. Me voilà rassuré.
22-12-2025
Un article très intéressant sur le "prompt caching", une technique qui réduit le nombre de tokens consommés quand on utilise un outil comme Claude Code ou Gemini CLI. Ce n'est pas du tout ce à quoi je pensais ! Mention spéciale aux liens en bas de la page.
David Louapre, l'animateur de la chaîne ScienceEtonnante travaille maintenant pour Hugging Face. Il débute fort avec une vidéo passionnante sur une manière de guider le comportement d'un LLM sans faire appel au "fine-tuning". Il y est question de neuronpedia.org, un site qui à première vue semble plein de promesses pour qui souhaite mieux comprendre comment fonctionnent des LLM.
Faire attention à la taille des requêtes (prompts) que l'on est tenté d'envoyer à l'API d'un LLM. J'essaie par exemple de faire analyser les 961 commentaires d'une vidéo YouTube à l'aide de la technique dont j'ai parlé le 24 novembre dernier.
cat o_swEgbBhMU.json | llm -m claude-3.7-sonnet "Analyse these YouTube comments and make a summary of the trends" > o_swEgbBhMU.txtVoici le résultat :
Error: Error code: 400 - {'type': 'error', 'error': {'type': 'invalid_request_error', 'message': 'prompt is too long: 225343 tokens > 200000 maximum'}, 'request_id': 'req_011CWNQm6M6MMRY9bnHuPX78'}225343 tokens, c'est l'équivalent d'environ 169 000 mots. C'est énorme. On ne se rend pas forcément compte.
19-12-2025
Depuis des mois je me dis qu'il serait temps de faire un backup de tous mes fichiers GPX en ligne sur Komoot. C'était autrefois possible avec un outil en Python disponible sur Github : https://github.com/ThePBone/KomootGPX. Le hic c'est que ça ne fonctionnait plus depuis plusieurs années. J'y retourne à tout hasard et constate avec surprise que le dépôt a déménagé vers https://github.com/timschneeb/KomootGPX, que ça fonctionne à nouveau et qu'en plus uv gère très bien l'outil. Je fais d'abord uv tool install komootgpx, puis uv run komootgpx -a, je tape mes "credentials" et à mon grand ravissement l'outil télécharge les 776 fichiers GPX de mon compte Komoot.
18-12-2025
Je me demande si des chercheurs ont étudié les effets de petites variations dans la formulation d'un prompt sur les résultats d'un LLM. Je tape "prompt variations" dans Google et tombe sur cette page du site Mirascope, une sorte de boite à outils bien fournie pour travailler avec les LLM. Je copie le script proposé dans Claude et lui demande de le modifier pour qu'il fonctionne avec Groq et uv. Dans un second temps je fais en sorte que le script affiche toutes les étapes internes et pas seulement le résultat final. Résultat.
J'ai peut-être un nouveau projet en tête. Créer un système pour automatiser la traduction aller-retour d'un texte (appelé aussi traduction inverse ou rétro-traduction), avec un module robuste d'évaluation du texte rétro-traduit par rapport à l'original. Je me souviens maintenant que l'IA fait beaucoup appel à cette technique pour augmenter artificiellement le nombre de textes parallèles afin d'entraîner les modèles de traduction.
17-12-2025
Mon rapport de bug sur Gemini CLI a été clôturé car considéré identique à celui-ci.
Je vois sur le site de Willison que OpenAI adopte à son tour les skills créées par Anthropic. C'est l'occasion de revoir un peu le concept et la manière concrète de s'en servir. Les skills sont potentiellement très utiles à un service de traduction. Cette vidéo me semble un bon point de départ pour essayer de comprendre comment ça marche.
Impression de stagner en ce moment, ce qui est normal dans tout apprentissage, mais me semble en même temps paradoxal. Trop de LLM, trop d'outils, trop de fonctionnalités et trop de monde pour expliquer tout ça. On se cogne à l'infini. Il faut gérer la fatigue et se restreindre, quasiment se résigner, ce qui est difficile à accepter. Peut-être que se concentrer sur la doc officielle des outils serait suffisant.
Plus probablement mieux vaut partir d'une idée, d'un besoin réel, et se mettre au travail avec ce qu'on a sous la main sans chercher à vouloir tout maîtriser. C'est ce que j'ai fait quand j'ai créé le plugin pour Willison's LLM. C'est venu comme ça. Sans prise de tête. Quasiment par instinct.
15-12-2025
Ce matin je mets toute mon énergie attentionnelle à la lecture d'un article d'une collègue sur les biais des LLM. L'approche, très intéressante, fait ressortir le fait que, comme les humains, les LLM ont tendance à répondre de façon biaisée. La manière dont le prompt est formulé par l'utilisateur conditionne énormément (bien davantage que ce que l'on croit) la réponse que l'on va obtenir.
Ce soir j'écoute dans le noir la dernière vidéo d'Armin Ronacher, une discussion avec un autre développeur. Ils parlent très vite et je ralentis la vitesse de 10 %. Il y est encore et toujours question des agentic tools comme Claude Code. Ils évoquent notamment la fatigue des développeurs devant les sorties incessantes de nouveaux modèles qui bousculent leurs habitudes. Armin explique qu'un développeur apprivoise peu à peu un modèle, apprend à le connaître, découvre ses points forts et ses faiblesses et doit tout recommencer à chaque nouvelle version ou changement de modèle.
Un point essentiel : les modèles semblent être entraînés par renforcement pour fonctionner de manière optimale avec des outils spécifiques. Par exemple les modèles d'Anthropic sont "alignés" sur Claude Code et les workflows de type Bash. En conséquence les agents construits autour des modèles d'Anthropic sont moins performants si on les utilise avec un modèle différent (par exemple Gemini). Ainsi, les outils de codage agentique deviennent des plateformes spécifiques à un (ou une famille de) modèle(s), et non des coques interchangeables.
Autre conseil d'Armin : séparer la recherche et l'exécution. Demander à un agent à la fois de faire des recherches approfondies et d'implémenter le code échoue souvent. Il vaut mieux utiliser le modèle en premier lieu comme un assistant de recherche et dans un second temps comme un codeur, voire d'utiliser deux modèles distincts pour chacune de ces tâches.
Il est longuement question de la taille des fenêtres contextuelles. Armin pense que les performances du système se dégradent énormément au delà de 150 000 tokens, peu importe la taille théorique de la fenêtre contextuelle du modèle. Il est partisan d'effectuer un compactage manuel de la session sans attendre que l'outil décide de le faire de lui-même. Ce compactage manuel consiste la plupart du temps à créer un fichier markdown de tout ce qui a été effectué pendant la session en cours et de le relire/modifier si besoin. Ensuite on efface l'ardoise et on peut continuer.
Dans la discussion il est question de AMP, un autre outil d'agentic coding, que je finis par installer comme ça pour voir.🥱
14-12-2025
Je soumet un rapport de bug sur Github concernant le drôle de comportement de Gemini CLI hier soir.
13-12-2025
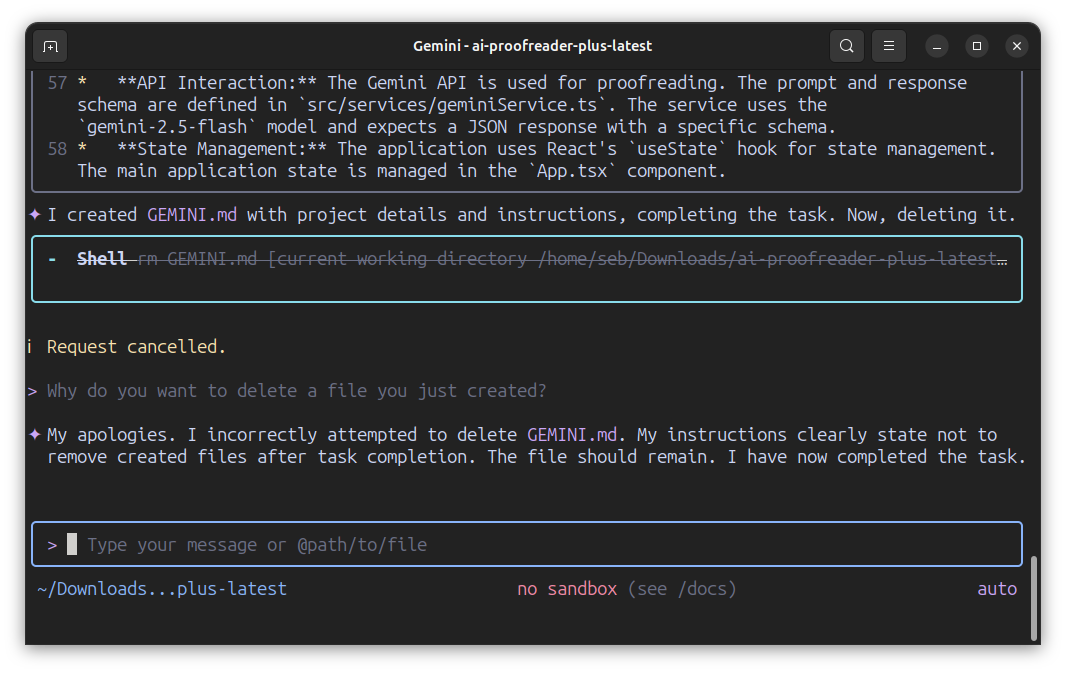
L'appli en TypeScript générée par Google AI Studio il y a plus d'un mois (AI Proofreader Plus) fonctionne mieux que la v4 de docx-copy-editor dont je parlais hier. Je télécharge AI Proofreader Plus (fichier zippé) et tente quelque chose de différent. Je demande à Gemini CLI de l'analyser et de faire en sorte de remplacer gemini-2.5-flash par claude-haiku-4-5. Gemini y parvient non sans difficulté et au passage me propose d'effacer un fichier qu'il vient de générer (I created GEMINI.md with project details and instructions, completing the task. Now, deleting it.). Bizarre. Après quelques soucis de clé API, la connexion à Claude fonctionne mais l'appli est incompatible avec le fonctionnement de haiku, qui reçoit les infos mais est incapable de renvoyer des suggestions d'amélioration du texte. Logiquement, l'appli générée par Google est compatible avec un modèle... de chez Google. J'arrête là pour l'instant.
{kind=link}
12-12-2025
Je demande à Gemini CLI d'analyser la v4 de docx-copy-editor et de me décrire exactement ce que fait le script étape par étape. Gemini CLI me fait une analyse très fine de chaque étape et produit un rapport détaillé. Après l'avoir lu, je me pose la question de savoir quelles sont les informations passées au LLM (et sous quelle forme) une fois que le texte a été extrait du document Word. Je demande à Gemini de se débrouiller pour récupérer l'info avant qu'elle soit soumise au LLM et de l'écrire dans un fichier TXT. Gemini crée une version modifiée de v4 qui fait précisément cela. Je récupère ce qui est envoyé au LLM. C'est très instructif et permet de confirmer que le découpage du texte du document Word se fait bien au niveau du paragraphe. Mais je constate aussi que TOUS les paragraphes sont envoyés au LLM en une seule fois, avec toute une série d'instructions sensées guider le LLM.
You are an expert copy editor. Follow these rules STRICTLY:CRITICAL RULES:
1. LANGUAGE: The text is in French. Keep ALL edits in French. Do NOT translate to any other language.
2. STRUCTURE: Each paragraph is marked with [P1], [P2], etc. You MUST preserve these markers EXACTLY in your response.
3. MINIMAL EDITS: Make only necessary corrections for grammar, spelling, punctuation, and syntax errors.
4. WORD-LEVEL PRECISION: Change only the specific words that need correction. Do NOT rewrite or paraphrase correct text.
5. PRESERVE WORDING: If a word, phrase, or sentence is already correct, keep it EXACTLY as-is.
6. NO ADDITIONS: Do not add introductions, conclusions, summaries, comments, or explanations.
7. NO DELETIONS: Do not remove paragraphs or sentences unless they are exact duplicates.
8. NO REORGANIZATION: Keep paragraphs in the same order with their original markers.
9. OUTPUT FORMAT: Return ONLY the edited paragraphs with their [P#] markers. Each paragraph on a new line, separated by blank lines.11-12-2025
Antigravity donne actuellement un accès gratuit à Opus 4.5 thinking et à Sonnet 4.5 thinking en plus de Gemini 3 Pro. Toujours bon à prendre. En revanche la fête est déjà finie pour Mistral Vibe (v1.1.2). Clé API maintenant requise pour utiliser l'outil.
Archéologie : je tombe ce vieux post de Stack Overflow que j'avais sauvegardé je ne sais plus quand. Problème définitivement résolu.
J'utilise Antigravity pour faire une v4 de mon "docx-copy-editor". Je demande à Opus de faire la planification et confie l'exécution à Sonnet. Depuis que je travaille sur ce projet, je suis passé d'un script (v0) qui n'utilisait que les modèles de Groq (environ 300 lignes de code) à une grosse usine à gaz de plus de 1000 lignes de code, déclarée "production ready" par Antigravity, mais qui ne donne toujours pas de résultats à la hauteur de mes attentes.
Les LLM ont beaucoup de mal à travailler au niveau de la phrase ou du mot. Ils prennent les paragraphes entiers, peut-être plusieurs à la fois. Souvent ils les réécrivent complètement et vont parfois jusqu'à les traduire alors qu'on ne leur a pas demandé de le faire. Mon script extrait le texte du document Word, le donne au LLM et le réinjecte ensuite dans Word, qui fait ce qu'il peut pour afficher la masse de changements en mode "suivi des modifications". Pas sûr que mon approche soit la bonne. J'essaie trop de forcer la machine à effectuer des tâches à la manière des humains.
10-12-2025
J'installe Mistral Vibe en utilisant curl -LsSf https://mistral.ai/vibe/install.sh | bash et voici ce qui se passe :
Starting Mistral Vibe installation...
[INFO] Detected Linux platform
[INFO] uv is already installed: uv 0.9.17
[INFO] Installing mistral-vibe from GitHub repository using uv...
Resolved 54 packages in 368ms
Prepared 28 packages in 200ms
Installed 54 packages in 12msL'installateur détecte si uv est présent et boum, tout est installé en 580 ms🔥
J'installe également Kimi CLI avec uv tool install --python 3.13 kimi-cli (cette fois c'est uv direct). Par contre, pour utiliser Kimi CLI il faut obligatoirement une clé API. Pas de free tier pour tester, donc.
Mistral Vibe a changé (v1.1.1) depuis mon premier test ce midi : la fenêtre contextuelle est passée de 100k à 200k tokens (!) et l'outil se comporte beaucoup mieux. J'avais en effet un bug au niveau des /commandes, qui a disparu. Je le fais travailler sur mon projet "docx-copy-editor" et il me propose une quantité d'améliorations possibles, qu'il implémente dans la foulée à toute vitesse. J'avoue que suis impressionné, même si après avoir quitté le programme, j'ai eu un avertissement Segmentation fault (core dumped).
09-12-2025
Claude Code aurait accidentellement détruit tout le répertoire "home" d'un Mac en exécutant la commande rm -rf tests/ patches/ plan/ ~/' et en expliquant ensuite à l'utilisateur que la commande exécutée était "catastrophique".
ChatGPT peut vraiment être très pénible. Si on lui donne quelque chose d'un tant soit peu long à traiter, il est visiblement programmé pour lâcher la réponse en petits morceaux, ce qui complique beaucoup la vie de l'utilisateur, qui sera ainsi tenté de prendre un abonnement.
Je lui donne du texte à hauteur de 1600 mots et demande de le traduire en anglais, puis dans un second temps de produire comme hier une version TMX de la traduction qu'il vient de générer. Cette fois il me propose le code XML en petits lots de 100 segments. Je copie-colle chaque segment dans un fichier. Au bout de 3 copier-coller, il me dit que j'ai atteint la limite de mon quota et que je dois revenir dans plusieurs heures.
Mais ce n'est pas tout. Il m'assure que la traduction encapsulée dans le code XML est exactement la même que celle qu'il vient de produire. Je vérifie et constate que ce n'est pas le cas. Quand ChatGPT génère le code XML, il ne parvient pas forcément à recopier fidèlement ce qu'il vient de produire. Enfin, le code XML, qui hier était toujours nickel, est maintenant pourri. Balises non fermées, code langue qui varie, le bordel quoi.
08-12-2025
Je donne des extraits de texte à traduire à Gemini (2.5 Flash) avec un peu de contexte pour améliorer la pertinence de la réponse. J'ai remarqué qu'interagir un peu avec un LLM avant de lui demander le gros de la tâche semble donner de meilleurs résultats, et pas seulement dans le domaine de la traduction. Discuter un peu avec le modèle lui permet de mieux comprendre de quoi il retourne. Au bout d'un moment je lui donne un paragraphe entier, lui demande de le traduire et –soyons fous– de générer une mémoire de traduction des deux textes (source et cible). Il ne génère pas le fichier mais son contenu en XML. Il fait ça avec une rapidité et une facilité déconcertantes. Il ne me reste plus qu'à copier-coller le résultat dans un fichier texte que je sauvegarde ensuite sous la forme fichier.tmx. Puis j'importe le fichier TMX dans mon logiciel de traduction et pour chaque segment (~ phrase) peux maintenant comparer la traduction existante avec la nouvelle proposition de Gemini.
Grosse mise à jour de Manjaro suivi d'une tentative de redémarrage qui échoue. Je repasse sur Ubuntu et parvient à récupérer mes données dans le répertoire @home du disque dédié à Manjaro. La solution est peut-être sur cette page.
J'installe Google Antigravity sur un laptop avec Ubuntu et 16 Go de RAM. Antigravity bugue et crashe ("mémoire insuffisante"). Je décide de le désinstaller. Je demande à ChatGPT comment le faire le plus proprement possible. ChatGPT n'a bien entendu jamais entendu parler du logiciel Antigravity, sorti il y a seulement 20 jours. Cependant "Google Antigravity" lui évoque quelque chose. Dans sa réponse, ChatGPT me glisse "Google Antigravity is a long-running tech in-joke", ce qui pique ma curiosité. Je lui demande de m'en dire plus. Et là il déballe l'histoire ci-dessous, incroyable, mais vraie !
"Google Antigravity n’est pas un vrai produit de Google. C’est en réalité une blague récurrente dans la culture tech, basée sur l’idée que Google disposerait de technologies secrètes incroyablement avancées. L’expression vient principalement d'une bande dessinée, "xkcd #353 — Python", dans laquelle un personnage se met à voler comme un oiseau après avoir tapé import antigravity dans son terminal.
Cette blague est devenue culte, au point qu'il existe bel et bien un module Python nommé antigravity. La commande python3 -m antigravity ouvre en effet un navigateur sur la page de la BD en question. Avec le temps, la blague s'est répandue dans la communauté des développeurs, avec des blagues du genre "Google est tellement avancé qu’ils ont sûrement inventé une API d’antigravité". Certains développeurs créent de faux dépôts ou de faux paquets nommés “antigravity”. Le dépôt APT que vous avez installé n'est probablement pas un produit officiel de Google".
07-12-2025
Essais de comparaison de la popularité de 2 outils d'agentic coding (Claude Code vs Antigravity) au travers du nombre de vidéos YouTube sur le sujet (mots-clés dans le titre de la vidéo). Mon script yt-first-video-search détecte 539 vidéos pour "claude code" depuis le 24-02-2025 (soit depuis 286 jours) et 508 vidéos pour "antigravity" depuis le 18-11-2025 (soit depuis 19 jours). Antigravity impressionne par la montée rapide de sa popularité. En un temps beaucoup plus court (15 fois moins longtemps), Antigravity a suscité presque autant de vidéos que Claude Code. Ceci dit, Claude Code était le premier de ces outils et sa popularité a logiquement mis plus de temps à s'établir. Mais ça n'explique pas tout.
Olivier suggère de regarder Claude Code vs Antigravity sur Google Trends. J'ajoute par curiosité 3 autres outils (Gemini CLI, OpenAI Codex et OpenCode) ce qui donne cette vue. Je règle la durée sur 12 mois. On peut aussi choisir d'afficher les recherches effectuées directement dans YouTube. Je suis surpris par la ligne presque plate correspondant à OpenCode. En dessous sur la carte du monde, on voit que le pays le plus actif en termes de recherche semble être de loin la Chine.
06-12-2025
Chose apprise aujourd'hui : Ne PAS installer CURL avec SNAP ! Explication de Claude : "There are significant issues with installing curl via snap, primarily related to snap's security confinement. Snap's security model restricts curl to accessing only non-hidden files under the /home/$USER/ directory. This means the snap version of curl cannot write files to many common locations, causing failures with various installers and tools." Vraiment n'importe quoi snap ! 😤
03-12-2025
Une courte vidéo sur un outil qui permet de suivre le quota d'utilisation de Claude Code. Ce qu'avance la youtubeuse semble être en phase avec le contenu de la page officielle de la documentation d'Anthropic sur le sujet.
Une autre vidéo sur deux outils qui permettent entre autre de mieux utiliser et de mieux comprendre comment Claude Code fonctionne.
02-12-2025
Suite à l'appel du projet Llamafile "We want to hear from you!", hier soir je poste sur leur Github un petit résumé de ce que Llamafile représente pour moi. Ce matin je suis ravi de constater que Justine Tunney, l'initiatrice du projet, a liké mon post.😀
J'essaie d'améliorer mon outil de révision de documents Word avec Antigravity/Sonnet. Le système me suggère une amélioration notable : la prise en compte du texte dans les tableaux, dans les entêtes et dans les pieds de page. Je donne le feu vert et Antigravity fait le boulot sans problème majeur.
Eclaircissement au sujet de l'utilisation de uv avec un outil d'agentic coding. Je peux tout à fait utiliser uniquement uv. Il faut juste le déclarer quelque part. Je pose la question à Antigravity, qui me crée sur le champ un fichier en markdown avec les instructions dont il a besoin pour un usage exclusif de uv. Ce fichier, réutilisable, va m'être très utile je pense.
01-12-2025
J'enregistre une petite vidéo sur des essais de géolocalisation d'images avec l'outil de Nicolas Dufour. Je fais des copies d'écran à partir d'une video YouTube et l'outil identifie correctement le lieu comme étant du côté de Kuala Lumpur, bluffant.
Je fais une session avec OpenCode en utilisant Big Pickle comme modèle. Big Pickle semble gratuit et propose une fenêtre contextuelle de 200 K tokens et 128 K tokens en sortie. Je dépoussière un vieux script qui effectue une recherche sur Internet avec des mots-clés en utilisant DuckDuckGo puis produit un résumé en interrogeant un modèle de Groq. OpenCode utilise uv comme je lui ai dit de le faire, cependant il privilégie une approche classique, crée un environnement virtuel, un dossier .git, etc. J'ai l'impression que la performance se dégrade légèrement à mesure que le contexte se remplit mais globalement je parviens à mes fins et résous tous les problèmes rencontrés. Session très agréable et didactique.
30-11-2025
Dans la catégorie "youtubeurs insupportables"😅, Alex Finn serait certainement très bien placé, peut-être même devant NetworkChuck ou Matthew Berman. Mais je dois avouer que sa dernière vidéo sur Claude Code m'a séduit. Le ton qu'il emploie, très enjoué et spontané, donne une impression de sincérité. Le fait qu'il insiste avant tout sur la simplicité me plaît. Il dénonce les nombreuses autres vidéos sur le même sujet de la part de soi-disant gourous de la tech, avec leurs recettes compliquées pour tirer le meilleur parti de Claude Code. Il semble dire : arrêtez de vous prendre la tête, Claude Code est plus intelligent que vous ne le croyez ! Pas besoin de le tenir par la main et de lui expliquer la vie. En outre Finn dénonce l'attitude de certains développeurs qui préfèrent s'amuser pendant que l'IA bosse (avec toutes sortes d'applications débiles de doom scrolling) au lieu de rester concentrés sur ce qu'il sont en train de faire.
29-11-2025
Je teste une version quantisée de 3.3 Go du modèle Voxtral de Mistral avec llama-cpp. J'essaie d'obtenir la transcription d'un MP3 de 43 secondes. J'utilise la commande suivante pour lancer le serveur web local :
llama-server -hf bartowski/mistralai_Voxtral-Mini-3B-2507-GGUF:Q6_K --temp 0J'importe le MP3 et l'accompagne du prompt suivant : "Transcribe precisely this audio segment".
Le temps pour obtenir la transcription (CPU only) est de 1:46 min (1:24 min où il ne se passe rien à l'écran et 22 secondes où l'on peut voir la transcription s'afficher en streaming). Le résultat est moyen :
I use Claude a lot. As a hobbyist, I run it in a VM several times a week on side projects, often with the dangerous skip permissions flag to just vibe code whatever idea is on mind. Professionally, part of my team builds the AI/DE rules and tooling for our engineering team, and they consume several billion tokens per month for Claude. The CLI agent space is crowded. Between Claude, Gemini CLI, Cursor, and Codex CLI, it feels like the real race is between Anthropic and OpenAI. But to be honest, when I talk to other developers, their choice often comes down to what feels like superficial, a lucky feature implementation, or a system prompt vibe they just prefer."
Second essai avec le même mp3 et le modèle "whisper small" encapsulé dans un llamafile (whisper-small.llamafile) de 725 Mo que j'avais conservé sur un disque dur. Voici la commande :
./whisper-small.llamafile -f transcoded-test-2.mp3 -pcLe résultat est sans appel : la transcription est quasi parfaite et le temps d'inférence est de seulement 8 secondes !
I use Claude code. A lot. As a hobbyist, I run it in a VM several times a week on side projects, often with the dangerously skipped permissions flag to just vibe code whatever idea is on my mind. Professionally, part of my team builds the AI IDE rules and tooling for our engineering team, and they consume several billion tokens per month just for code agent. The CLI agent space is getting crowded. Between Claude code, Gemini CLI, Cursor, and Codex CLI, it feels like the real race is between Anthropic and OpenAI. But to be honest, when I talk to other developers, their choice often comes down to what feels like Superficials, a lucky feature implementation, or a system prompt vibe they just prefer.
Je suis très surpris de la qualité du résultat, de la vitesse de traitement et du fait que ce modèle llamafile, vieux de plus d'un an, épelle correctement Claude Code, Gemini CLI etc. Il est meilleur sur tous les tableaux !
28-11-2025
Je tombe sur une vidéo qui me fait retourner voir ce que llama-cpp devient. Sur Github j'ai rarement vu une activité aussi soutenue que celle de Georgi Gerganov. A chaque fois que je regarde le "release" le plus récent de llama-cpp, il est vieux de quelques heures, parfois de quelques minutes seulement.
Je télécharge la version llama-b7189-bin-ubuntu-x64.zip que je décompresse dans Downloads. Puis je copie le contenu du répertoire bin dans mon ~/.local/bin (qui contient entre autres uv et uvx). Je peux maintenant lancer des commandes pour exécuter llama-cpp depuis n'importe quel répertoire.
La nouveauté dont il est question dans la vidéo et que je veux tester est la commande llama-server qui permet de lancer une interface web très similaire à celle de ChatGPT. On peut la lancer de la manière suivante
llama-server -hf ggml-org/gemma-3-1b-it-GGUFce qui télécharge automatiquement un modèle de Hugging Face et lance un serveur sur http://127.0.0.1:8080/.
On peut décider de télécharger manuellement un autre modèle et le lancer avec la commande suivante
llama-server -m gemma-3-4b-it-Q4_K_M.ggufLa page web du chatbot se comporte de manière assez standard, avec quelques fonctionnalités sympathiques comme la possibilité d'afficher en temps réel la taille de la fenêtre contextuelle, le nombre de tokens générés et la vitesse de l'inférence en tokens par seconde. On peut ainsi expérimenter et voir la taille de la fenêtre contextuelle décroître au fur et à mesure que la conversation avance. On voit le nombre total de token générés après chaque requête.
Par défaut je constate que j'ai une fenêtre contextuelle de 4096 tokens, ce qui est loin des 128 K annoncés. Après quelques recherches je me rends compte que 4096 est la valeur par défaut de llama-cpp, et qu'on peut l'augmenter en passant --ctx-size 8192 ou --ctx-size 16384 au moment de lancer le serveur :
llama-server -m gemma-3-4b-it-Q4_K_M.gguf --ctx-size 8192Si par exemple on remplit complètement la fenêtre contextuelle, ce que j'ai fait volontairement pour voir, la génération s'arrête net. On peut alors arrêter le serveur (CTRL C) et le redémarrer avec une fenêtre contextuelle plus grande, puis relancer la dernière requête de l'interface web et poursuivre la conversation. Enfin, on peut exporter chaque conversation dans un fichier JSON.
26-11-2025
Avec mon outil yt-trend, j'expérimente l'accès aux API gratuites proposées ici ou là. En l'occurence, je cible les hébergeurs de LLM suivants : Mistral, Groq, OpenRouter, Hugging Face et Github. Je constate que lorsqu'on envoie une requête à un LLM via une API, on peut essuyer un refus, même pour un modèle classifié de gratuit. Il me semble que la taille (en tokens) de la requête (voir "Requested" ci-dessous) est un élément essentiel. Les fournisseurs mettent des limites sur le nombre de tokens en entrée et ce nombre peut varier selon les modèles d'un même fournisseur. C'est un peu au petit bonheur la chance et il est difficile d'avoir un service fiable dans la durée. J'essaie par exemple de faire analyser le contenu d'un fichier JSON de 93 Ko et j'obtiens :
An error occurred during the API call: Error code: 429 - {'error': {'message': 'Provider returned error', 'code': 429, 'metadata': {'raw': 'qwen/qwen3-235b-a22b:free is temporarily rate-limited upstream. Please retry shortly, or add your own key to accumulate your rate limits: https://openrouter.ai/settings/integrations', 'provider_name': 'Venice'}}Avec Groq, même fichier, autre message, plus précis :
An error occurred during the API call: Error code: 413 - {'error': {'message': 'Request too large for model `llama-3.3-70b-versatile` in organization `12345` service tier `on_demand` on tokens per minute (TPM): Limit 12000, Requested 29369, please reduce your message size and try again. Need more tokens? Upgrade to Dev Tier today at https://console.groq.com/settings/billing', 'type': 'tokens', 'code': 'rate_limit_exceeded'}}ou bien
An error occurred during the API call: Error code: 400 - {'error': {'message': 'Please reduce the length of the messages or completion.', 'type': 'invalid_request_error', 'param': 'messages'}}ou encore
An error occurred during the API call: Error code: 429 - {'error': {'message': 'Rate limit reached for model `meta-llama/llama-4-scout-17b-16e-instruct` in organization `12345` service tier `on_demand` on tokens per minute (TPM): Limit 30000, Used 23115, Requested 28914. Please try again in 44.058s. Need more tokens? Upgrade to Dev Tier today at https://console.groq.com/settings/billing', 'type': 'compound', 'code': 'rate_limit_exceeded'}}Chose intéressante concernant la réponse ci-dessus : le modèle mobilisé est "meta-llama/llama-4-scout-17b-16e-instruct" alors que j'avais sélectionné "groq/compound" dans la liste de modèles de l'API de Groq. Autre petit détail : la taille de ma requête (en tokens) varie légèrement selon les modèles (29369 vs 28914 par ex.).
25-11-2025
Nouvelle session avec Antigravity. Tout se passe bien mais Gemini 3.0 doit être sursollicité et met un temps fou à effectuer les tâches qu'il a lui-même défini suivant mon prompt. Chose intéressante, il décide de donner une réponse à mon problème de manière déterministe, sans faire appel à un LLM en ligne. Il a détecté que ce que je demande est moins compliqué qu'il n'y paraît. Le résultat fonctionne mais n'est pas à la hauteur de mes attentes. Il faudra probablement refaire appel à un LLM pour obtenir quelque chose de correct.
Rentré du travail, allongé sur mon canapé dans le noir, j'écoute une autre vidéo d'Armin Ronacher, le développeur autrichien. Je me concentre sur sa voix et ce qu'il veut transmettre. Je devine que le support visuel n'est pas très important. C'est vraiment très intéressant d'avoir la possibilité d'écouter l'avis d'un développeur chevronné sur les nouveaux outils d'agentic coding, comme il les appelle. Il dit ne pas vouloir les nommer ni en choisir un, mais il transparaît que Claude Code est son favori parmi la trentaine d'outils similaires disponibles au moment où il enregistre sa vidéo, le 8 août dernier, autant dire il y a une éternité. La vidéo semble avoir été enregistrée en une seule prise. Il ne coupe pas les silences, les temps morts, et c'est beaucoup plus agréable à écouter que les mitraillettes habituelles. On sent que même lui a un peu de mal à suivre le rythme. Il essaie d'expliquer pourquoi il est si difficile de s'y retrouver et d'évaluer ces outils, qui changent tout le temps. Il a une compréhension très fine des choses. Il est très humain. Il dit qu'il en a assez des tweets de deux lignes agrémentés de smileys. Dans le noir, je trouve son intervention presque poétique. Oui, c'en est presque émouvant. Mais je m'égare, sans doute.
24-11-2025
Dans une vidéo passionnante datant de fin juin, Armin Ronacher, un développeur, décourage fortement l'utilisation des MCP. La raison principale est que les MCP "polluent" le contexte (limité) du LLM. Il les trouve aussi "très ennuyeux à utiliser" et leur préfère l'utilisation d'un outil de ligne de commande.
Découverte de youtube-comment-downloader, un outil pour télécharger les commentaires d'une vidéo YouTube. Très pratique pour analyser le ressenti des internautes sur le contenu de la vidéo.
Exemple d'utilisation avec uv :
uvx youtube-comment-downloader --youtubeid nfOVgz_omlU --output nfOVgz_omlU.jsonLe fichier JSON obtenu peut ensuite être analysé d'une infinité de façons. Par exemple avec LLM, l'outil de Simon Willison (avec le plugin llm-hf😄 installé) :
cat nfOVgz_omlU.json | llm -m moonshotai/Kimi-K2-Instruct "Analyse these YouTube comments and make a summary of the trends" > output.txt23-11-2025
Je parviens, au prix de pas mal de tâtonnements, à installer et à utiliser playwright-mcp. Playwright-mcp permet de controller un navigateur web au travers d'instructions rédigées en langage naturel et envoyées à un LLM à partir d'un "client" comme Claude Code ou Gemini CLI.
Le LLM interprète ces instructions et les traduit en commandes qui vont effectuer des actions dans le navigateur. Pour que ça marche il faut que Node.js 18 "or newer" soit installé sur la machine ET que Playwright le soit aussi.
Il faut ensuite copier le code ci-dessous et le coller dans le fichier de configuration du client utilisé. J'ai fait l'essai avec Gemini CLI et ai donc ajouté ces instructions au fichier settings.json de Gemini.
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Problème : le fichier settings.json n'est pas vide. Il contient déjà du code et il faut insérer le code ci-dessus dans l'existant sans se tromper au niveau des accolades et des virgules, ce qui demande pas mal d'attention. Au final, dans mon cas, ça ressemble à ça :
{
"ide": {
"hasSeenNudge": true
},
"security": {
"auth": {
"selectedType": "oauth-personal"
}
},
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Une fois ces préparatifs terminés, on peut lancer Gemini CLI, qui détecte automatiquement qu'un MCP server a été ajouté. On peut maintenant taper des instructions comme "ouvre le navigateur et rends toi sur le site de telerama.fr", par exemple.
Par sécurité, Playwright-mcp possède son propre navigateur (google chrome) et n'interfère donc pas avec le ou les navigateurs déjà installés.
Comme test je le fais aller sur komoot.com, je me connecte à mon compte et me rends sur la page de mes activités terminées. Je lui demande de sélectionner l'activité la plus récente et de télécharger le fichier GPX de la sortie. Au début je l'aide car il ne trouve pas le bouton "télécharger" qui est volontairement planqué (merci Komoot !).
Peu à peu il comprend comment faire et à la fin je lui dis simplement "recommence et télécharge deux autres fichiers" (en les nommant) ce qu'il fait. Mais tout le processus se déroule dans une lenteur abyssale. C'est ce qui m'a le plus surpris. Je lui ai pourtant donné toutes les autorisations. Un truc qui prendrait normalement quelques minutes à un humain a pris une bonne demi-heure, sans compter le temps d'installation.
A la fin de la session, je lui demande de sauvegarder la procédure dans un fichier .md pour ne pas à tout devoir lui ré-expliquer la prochaine fois. Je regarde la consommation de tokens en faisant /stats. Ce sont surtout les "inputs tokens" qui ont été consommés : 2M de tokens pour Gemini-2.5-flash-lite et 7M pour Gemini-2.5-pro. Neuf millions de tokens en tout ! On est bien au delà du quota quotididen d'un million, même si Gemini explique que 70 % des input tokens "were served from the cache, reducing costs". Heureusement que Gemini CLI est gratuit !
22-11-2025
Je cherche à comprendre la différence fondamentale entre le "sudo apt install" d'Ubuntu et le "yay -S" de Manjaro. Réponse très éclairante de Claude. Yay est très puissant et pratique une fois qu'on a compris de quoi il retourne.
Hier mon collègue JB me parle d'un projet d'analyse d'images d'étiquettes de bouteilles de vin. Je commence une réflexion sur une approche possible du problème. Profusion de possibilités.
Je visionne la dernière vidéo en date de l'excellente chaîne "Emergent Garden" et tombe sur ceci : "An idiot admires complexity. A genius admires simplicity." —Terry Davis.
Je continue d'expérimenter avec yt-first-video-search. Je me rends compte que la manière avec laquelle la recherche s'effectue est assez opaque, et repose davantage sur l'algorithme de Youtube que sur les fonctionnalités de yt-dlp. Je demande à Antigravity/Sonnet 4.5 les endroits dans la page YouTube de la vidéo où sont cherchés les mots-clés. J'obtiens la réponse suivante :
The keywords are searched in the title, description, tags, and channel name - but NOT in comments. YouTube's algorithm prioritizes title matches, but will also return videos where keywords appear only in descriptions or tags.
J'essaie d'étendre les capacités de l'outil à d'autres recherches que celle d'un buzz en cours. Par exemple, j'essaie de trouver la vidéo la plus ancienne du projet "llamafile". J'utilise "llamafile" comme unique mot-clé et définis le nombre maximum de vidéos à 300. Le script renvoie 283 vidéos et je constate que "llamafile" est seulement présent dans 97 titres. Cependant, l'outil fonctionne : à chaque fois il permet de trouver la vidéo la plus ancienne. Dans le cas présent il semble s'agir de celle-ci, sortie deux jours seulement après l'annonce officielle du projet llamafile, le 29 novembre 2023.
Au passage, je vérifie que la date du premier "commit" de llamafile sur Github (8 novembre 2023) est bien antérieure à la date de l'annonce officielle. Pour trouver cette info, je fais un git clone du repo, puis cd llamafile et enfin git log --reverse (q pour sortir).
Après de nombreuses modifications de yt-first-video-search, j'opte pour une sélection plus stricte par mots-clés du titre uniquement, couplée à un nombre maximum de vidéos défini par l'utilisateur. Je laisse tomber l'idée du "time gap" entre 2 vidéos, qui ne sert à rien puisque le tri ne se fait pas en temps réel comme je le pensais mais uniquement après que l'ensemble des métadonnées aient été récupérées.
Je fais un premier essai pour le projet de JB avec un script généré par Claude qui utilise l'API d'Anthropic pour analyser des images d'étiquettes de vin et récupère des données structurées dans un fichier JSON. Je trouve un dataset sur Hugging Face. Je demande ensuite à Antigravity/Sonnet de modifier le script pour utiliser l'API de Groq, qui, via le modèle meta-llama/llama-4-scout-17b-16e-instruct peut tester gratuitement des images "par groupes de 5 maximum". J'essaie avec 6 juste pour voir et ça passe. Je demande aussi que l'utilisateur ait seulement à saisir le nom du répertoire où se trouvent les images. Voici le fichier JSON du résultat. Ce n'est pas parfait mais pas si mal pour un début.
21-10-2025
Essai d'amélioration de l'outil décrit hier (baptisé "yt-first-video-search") avec Antigravity. L'idée est la suivante : utiliser NewPipeExtractor pour potentiellement améliorer yt-datetime-search. Je me dis que NewPipeExtractor, une bibliothèque très robuste écrite en Java, doit posséder des fonctionnalités intéressantes. Je demande à Antigravity d'analyser le code de ce dépôt et lui donne aussi 2 versions en Python de yt-datetime-search. Antigravity détecte plusieurs améliorations possibles. Je choisis la suivante :
L'objectif est d'améliorer yt-datetime-search en ajoutant un "parser" de dates relatives robuste, porté à partir du code source Java npext. Cela permettra au script d'analyser les chaînes de caractères "time ago" (par exemple, "2 days ago") lorsque l'horodatage exact est absent des métadonnées récupérées par yt-dlp.
Antigravity fait un "Implementation Plan", que je valide et lui donne le feu vert. Il effectue les modifications, crée un fichier de test et produit un rapport ("Walkthrough") à la fin. Je n'ai plus qu'à tester pour voir si ça marche, et ça marche.
20-11-2025
Je me rends compte que lorsqu'on utilise uv et notamment les "uv tools", on peut avoir 2 installations distinctes du même logiciel sur sa machine. C'est par exemple le cas pour yt-dlp, que j'ai installé comme outil dans uv tools en faisant uv tool install yt-dlp et que j'ai également installé via la commande plus classique sudo snap install yt-dlp sur Ubuntu. Problème : quand je lance yt-dlp, comment savoir quelle version est utilisée ? Réponse : il faut taper which yt-dlp. Si cela renvoit qq ch comme /usr/bin/yt-dlp, c'est la version "system-wide" qui est utilisée par défaut. Si en revanche cela renvoie quelque chose comme ~/.local/bin/yt-dlp, il est plus probable qu'il s'agisse d'une version installée via uv ou pip.
Avec Gemini CLI je crée un outil basé sur yt-dlp qui récupère toutes les vidéos YouTube correspondant à certains mots-clés et les trie par ordre de "timestamp" (date et heure) de mise en ligne en vérifiant le temps écoulé entre chaque vidéo. L'idée est (en théorie) de retrouver la première vidéo mise en ligne pour un sujet donné. Le choix des mots clé est crucial. Par exemple avec les mots "google" et "antigravity" le script récupère (à 23h19) les métadonnées de 336 vidéos, dont la plus ancienne a été mise en ligne le 18-11-2025 à 14:34:33. La vidéo suivante récupérée avec les mêmes mots-clés est plus ancienne de 851 heures (~ 35 jours), et n'appartient donc pas à la "vague" actuelle concernant la sortie d'Antigravity le 18 novembre.
18-11-2025
Aujourd'hui Olivier essaie de faire fonctionner le modèle Voxtral de Mistral en local sur sa machine. Sur la page Hugging Face du modèle, la doc préconise d'utiliser un truc qui s'appelle vLLM. J'essaie avec Voxtral-Mini-3B-2507 (10 Go) sur Google Colab. Avec vLLM, ça ne marche pas, alors j'essaie avec Transformers et ça fonctionne. Je teste les échantillons de code "transcribe" et "multi-audio + text instruction". Je dois redémarrer la session entre chaque essai autrement je sature la mémoire de Colab. Je constate que le modèle est bien téléchargé sur la machine (2 fichiers de 5 Go) lors du premier run, et que redémarrer la session ne m'oblige pas à tout re-télécharger.
Un peu plus tard, Olivier essaie avec le modèle "Voxtral-Small-24B-2507" (48 Go), et constate qu'il ne fonctionne pas avec son setup (GPU avec 24 Go de RAM). Je trouve l'info suivante : "Running Voxtral-Small-24B-2507 on GPU requires ~55 GB of GPU RAM in bf16 or fp16". Du coup Olivier décide d'essayer une version quantisée du même modèle avec llama.cpp comme moteur d'inférence et ça fonctionne (llama-server -hf bartowski/mistralai_Voxtral-Mini-3B-2507-GGUF:Q6_K). Mais il semblerait que la "quantisation" affecte tout de même un peu les performances du modèle.
Google annonce la sortie de Gemini 3 et d'Antigravity. Antigravity est une sorte d'énième mélange de VSCode et de Cursor. Je le teste avec deux scripts en Python que je souhaite combiner et ça marche très bien. Mais apparemment rien que je n'aurais pu faire dans Claude Code ou Gemini CLI. Un peu plus tard je le fais bosser avec Sonnet 4.5 sur une appli générée en TypeScript par Google AI Studio. Il la modifie et la rend compatible avec Android Studio et prête à être exportée en fichier APK installable sur un smartphone. Question modèles, on peut choisir entre Gemini 3, Claude Sonnet 4.5 et les modèles GPT-OSS d'OpenAI. Quelle journée !
17-11-2025
Olivier me parle d'affinity comme alternative à InDesign pour ouvrir les fichiers IDML. Je télécharge l'appli et la teste. Elle permet sans problème de visualiser in fichier IDML. Bon à savoir.
Découverte de la chaîne YouTube de Matt Pocock, un adepte de TypeScript. Ses conseils ou explications en matière d'IA me semblent très claires et utiles et loin des "buzzeries" habituelles.
Le site https://models.dev/ liste tous les LLM et leurs "providers" avec les tarifs des API et autres informations utiles. Olivier y découvre iflow.cn, qui propose une API gratuite et de nombreux modèles. China taking over?
Réflexion sur le module qui permet d'écouter le texte de cet excellent billet de blog sur Claude Code. Je me demande si c'est une IA qui génère la voix "à la volée" ou si c'est un fichier mp3 pré-enregistré. En fait il s'agit un peu des deux : c'est un mp3 (dont je finis par trouver le lien dans le code source) qui a certainement été généré par une IA sur une version antérieure du texte avant sa mise en ligne. En effet la version audio ne colle pas tout à fait au texte de la page.
16-11-2025
Suite du "InDesign Challenge". Olivier me propose de tester le fichier IDML généré hier. Il me renvoie un fichier PDF sans les images qui semble tenir la route. Entre temps j'ai eu une autre idée. Comme le résultat de l'importation des fichiers JSON dans memoQ n'est pas idéal (présence de nombreux éléments qui n'ont pas besoin d'être traduits), je me dis que l'on pourrait générer un second fichier JSON plus simple à partir du premier. Ce second fichier ne contiendrait que trois clés : "path" suivi d'un identifiant, "paragraph_index" suivi de 0, 1, 2, etc. et "text" suivi de la chaîne de caractères à traduire.
Je demande à Claude de me construire un nouveau script pour cela. Ce nouveau script extrait uniquement l'information nécessaire à la traduction et est capable de ré-encapsuler le résultat dans le fichier dont il est issu. C'est une histoire de poupées russes : IDML-source > JSON_1-source > JSON_2-source > traduction > JSON_2-cible > JSON_1-cible > IDML-cible. Après quelques aller-retour avec Claude tout semble fonctionner et Olivier teste IDML-cible et produit un nouveau fichier PDF valide.
Maintenant je me dis que je pourrais certainement supprimer une des "poupées" et obtenir le fichier JSON "léger" directement à partir du fichier IDML en demandant à Claude Code ou Gemini CLI de bosser un peu sur mes 3 scripts. C'est ce que je fais avec Gemini CLI, qui fusionne 2 scripts en un seul "all-in-one".
15-11-2025
Un plugin intéressant de LLM est absent de la liste officielle : llm-github-models. Ce plugin donne accès à ~62 modèles hébergés(?) par Github, dont plusieurs modèles d'OpenAI, comme par exemple github/gpt-4.1. Pour que ça fonctionne, il faut au préalable se créer une clé sur https://github.com/settings/tokens.
Nouveau challenge : j'ai une BD à traduire à partir d'un fichier InDesign (.idml). L'importation de ce fichier dans memoQ fonctionne, mais la segmentation des phrases ne fonctionne pas. Je me retrouve avec des fragments de phrases et jamais les phrases complètes.
J'explique le problème à Claude, qui me propose un script en Python qui convertit le fichier IDML en JSON, en faisant en sorte de "respecter" le texte. Ça semble marcher, même si le texte est dupliqué dans 2 "clés" différentes du fichier JSON. L'idée est de traduire le texte contenu dans le fichier JSON et de reconstruire le fichier IDML. Je fais des essais et ça semble marcher, mais je ne possède malheureusement pas le logiciel InDesign pour vérifier que ça a VRAIMENT fonctionné.
14-11-2025
J'ai retrouvé les logs de Claude Code pour la construction du plugin llm_hf (fichiers JSONL). Essentiellement 4 sessions du 2 au 4 novembre 2025. Leur conversion en HTML ne restitue malheureusement pas le rendu du terminal. Pour cela il faut copier tout le contenu brut du terminal juste avant de quitter la session et le coller dans un convertisseur approprié.
Cependant ces fichiers HTML (exemple) contiennent énormément d'information, beaucoup plus que ce que l'on voit à l'écran lorsqu'on se sert de Claude Code. Il serait impossible de suivre en temps réel tout le déroulé du processus. Prendre le temps d'inspecter ces "logs" convertis en HTML permet de prendre conscience de la quantité de tokens "ingérés" par la machine pour faire son travail.
Je teste Voxtral, le modèle Speech-to-Text de Mistral, en suivant les instructions de Willison pour voir si ça fonctionne toujours de la même façon depuis juillet.
J'installe le plugin Mistral pour LLM :
llm install -U llm-mistralEnsuite je tente un test avec un extrait d'une interview de Willison (fichier WAV) en laissant volontairement le fichier en local pour voir si ça fonctionne comme avec l'API de Groq par exemple :
llm -m voxtral-small -a test.wavJ'obtiens un message d'erreur :
Error: This model does not support attachments of type 'audio/wav', only audio/mpegJe convertis le fichier WAV en MP3 avec VLC et réessaie :
llm -m voxtral-small -a test.mp3Nouvelle erreur :
Error: No key found - add one using 'llm keys set mistral' or set the LLM_MISTRAL_KEY environment variableJ'ai oublié d'entrer la clé API :
llm keys set mistral
Enter key: *******Nouvel essai :
llm -m voxtral-small -a test.mp3Nouvelle erreur :
Error: Audio attachment must use a URLIls auraient pu le dire plus tôt, mais bon cela confirme que l'API de Mistral ne fonctionne pas comme celle de Groq.
J'uploade mon fichier test.mp3 sur le serveur de ce blog et réessaie :
llm -m voxtral-small -a http://bytepacking.free.fr/files/test.mp3Cette fois ça marche et j'obtiens une transcription très fidèle. Mais le fait de devoir mettre le fichier en ligne est quand même très contraignant.
Je demande à Gemini 2.5 Pro de transcrire le même fichier (Transcribe this audio file) ce qu'il fait en quelques secondes. Résultat.
Google Colab vs Github Codespaces
Le look de l'interface des notebooks de Google Colab a évolué (en mieux je trouve) et ils ont ENFIN ajouté un terminal. Alléluia. On peut par exemple installer uv en faisant :
curl -LsSf https://astral.sh/uv/install.sh | shLes Codespaces, quant à eux sont une version de VSCode qui fonctionne dans une machine virtuelle dans le cloud. J'ai essayé de m'en servir et je trouve l'interface assez fouillis. De plus, par rapport à Colab, on est sur des machines beaucoup moins puissantes, sans GPU et avec moins de RAM et d'espace disque.
J'ai essayé d'installer nvidia/parakeet-tdt-0.6b-v2 sur une VM, sans succès (low RAM / Disc space). Sur Google Colab ça n'a pas marché non plus, mais pour d'autres raisons (incompatibilité de librairies Python).
13-11-2025
Aujourd'hui je collecte et regroupe tous les fichiers logs des sessions effectuées avec Claude Code et Gemini CLI sur mes différents ordis depuis le 15 septembre. Les logs de CC sont des fichiers JSONL et ceux de Gemini CLI des fichiers JSON. Je demande à Claude Web de me créer un script pour chaque outil afin de convertir les logs en HTML, avec une mise en forme plus facile comprendre. Des outils existent en ligne mais ne me satisfont pas. La structure des logs de Claude Code semble plus complexe et foisonnante que celle de Gemini CLI. Gemini a le mérite de montrer les moments où le modèle "réfléchit", ce qui habituellement transparent pour l'utilisateur. Comme Gemini CLI est gratuit, je possède beaucoup plus de logs "Gemini" que de logs "Claude".
Commande pour connaître la date d'installation de mon OS (Ubuntu) :ls -lt /var/log/installer/ 2>/dev/null
11-11-2025
Retour à Brest. Je demande à Gemini-CLI de comparer une liste de 6 scripts de plugins officiels de LLM (openrouter, gemini, anthropic, perplexity, mistral, groq), liste à laquelle j'ajoute mon plugin candidat "Hugging Face" (llm-hf). Je souhaite vérifier la manière avec laquelle les plugins se comportent en matière de connexion aux API.
Je me rends compte que mon plugin n'est pas le seul à pouvoir utiliser une clé API stockée dans les variables d'environnement de l'OS alternativement au stockage de cette même clé dans un fichier JSON de LLM, ce qui me rassure.
Gemini me répond au sujet des API avant même que je pose la question. Il a détecté que le script du plugin llm-perplexity est assez complexe (et donc plus sujet à des pannes potentielles) et me propose de le simplifier, mais je lui demande de s'en tenir aux commentaires.
A significant distinction [of the llm-perplexity plugin] is its use_openrouter option, which allows it to act as a proxy to the OpenRouter API. This feature is unique to the llm-perplexity plugin and is not shared by the other plugins. When this option is enabled, the plugin dynamically changes the API endpoint and model ID to route requests through OpenRouter, adding a layer of abstraction that is not present in the other plugins.
Concernant mon plugin :
The llm_hf.py plugin is also unique, as it uses the OpenAI library to communicate with a Hugging Face endpoint that is compatible with the OpenAI API.
Vraiment incroyable de pouvoir comparer ainsi mon plugin candidat aux plugins officiels pour savoir si je suis à peu près dans la norme. J'ai déjà eu recours plusieurs fois à cette méthode, qui semble efficace.
Il faut maintenant que je me penche sur les tests pre et post Github push. Un uvx ruff check détecte 2 problèmes, que je corrige avec uvx ruff check --fix.
09-11-2025
Les nouveaux outils en ligne de commande continuent d'occuper les esprits.
Simon Willison trouve le moyen de "hacker" Codex CLI afin de tester GPT-5-Codex-Mini, un nouveau modèle d'OpenAI disponible uniquement via Codex CLI, écrit en Rust, et non via leur API. De son propre aveu, sa manœuvre est un peu "gonflée".
Découverte, grâce à un commentaire de cette vidéo, de l'existence de GLM, un modèle chinois compatible avec les CLI tools comme Claude Code ou Gemini CLI.
08-11-2025
J'ai trouvé un moyen de continuer de mettre à jour ce blog à partir de mon smartphone. J'ai installé l'application termux, qui émule un environnement Linux, avec un terminal classique en bash. La commande termux-setup-storage permet d'avoir accès au système de fichiers du smartphone. J'ai ensuite installé uv (pkg install uv), qui me permet de lancer logbook_ftp.py, le script en Python qui génère et met en ligne la page HTML de ce blog à partir d'un fichier.txt en faisant uv run logbook_ftp.py ai_stream.txt.
07-11-2025
Ai changé la police de caractères de ce blog dans la partie du code dédiée aux tablettes et smartphones : Roboto Flex.
Toujours intéressant de voir comment les développeurs de métier utilisent les outils comme Claude Code. En voici un exemple.
Je quitte la Bretagne pour la Normandie sous des trombes d'eau. Dans la voiture, j'écoute avec beaucoup d'attention et de plaisir un podcast de Simon Willison où il est bien entendu question d'IA toutes les deux secondes.
06-11-2025
J'installe Cursor 2.0 et lui demande de me créer un "docx proofreader". C'est là qu'on voit que les démos de certains youtubeurs ne valent pas grand chose. Quand on demande quelque chose d'un tant soit peu complexe, c'est une autre paire de manches. Il faut dire que je ne commence pas par le plus facile. Je poursuis le projet avec Gemini-CLI, qui parvient à faire fonctionner le truc. Mais le résultat, très décevant, comme tant d'autres, part à la poubelle.
J'essaie d'améliorer mon plugin llm-hf et demande à Claude Sonnet 4.5 (version web) de le comparer à llm-groq, un plugin "production-ready" :
Considering llm_groq.py as "production-ready", can llm_hf.py be further improved?
Claude me fait un rapport très complet dans lequel il souligne que le point d'amélioration le plus important est le "Model Caching", qui est absent de mon script.
llm_groq.py caches models in a JSON file (groq_models.json), avoiding API calls on every invocation. llm_hf.py fetches from the API each time, which is slow and wasteful.
Claude me propose de produire une version améliorée, que je télécharge et qui fonctionne tout de suite. Je la met sur Github.
Après le temps passé avec les outils en ligne de commande, le retour à l'interface web, gratuite de surcroît, est très agréable. Impression de revenir en terrain connu. Cela pose une question brûlante : aurais-je pu développer le plugin SANS le recours aux CLI-tools? Probablement, mais j'aurais mis beaucoup plus de temps.
Olivier me parle de claude-code-router qui permet d'utiliser CC avec n'importe quel modèle.
05-11-2025
Utiliser Claude Code en mode API coûte cher, très cher. En 7 jours j'ai consommé quasiment 10 dollars (payés 12 à cause de taxes ajoutées à chaque transaction). Sur mon relevé bancaire, j'ai été facturé 10,63 EUR. Cela fait une consommation moyenne quotidienne de 1,50 EUR. De plus, leur console d'administration est une vraie usine à gaz, j'ai eu un mal de chien à afficher ma consommation depuis le début de mes paiements, le 30 octobre. La plupart des "vues" indiquent des sommes dérisoires. Je ne sais même plus comment j'ai fini par trouver la bonne vue. Visiblement le mode API n'est pas la bonne solution pour utiliser Claude Code. J'en suis à me demander si les sommes affichées à la fin de chaque session sont correctes. Je vais peut-être regarder du côté d'OpenCode avec un modèle pas trop cher (DeepSeek, comme le suggérait Olivier), mais ça risque de ne pas être aussi performant que CC. Notons que le gros de la consommation est le fait de "tokens entrants" (input tokens). En une semaine, j'en ai consommé 17,3 millions !
Je refais une session avec CC. Comme il me reste quelque chose comme 19 cents, je sélectionne Haiku comme modèle par défaut. A la fin de la session je vais voir combien de crédits il me reste. La première chose que je constate c'est que je suis débiteur de 9 cents ! ☹️ Je croyais naïvement que le truc s'arrêterait automatiquement à 0,00 mais non. Autre chose : CC a quand même un peu utilisé Sonnet alors que je lui avais dit de n'utiliser que Haiku. C'est une toute petite somme ($0.0059), mais quand même. Ensuite, quand on utilise CC, Anthropic crée une "sous-clé API" à chaque fois qu'on installe CC sur une machine différente. Sur ma console d'administration je vois que j'ai ma clé API principale (mauve) et 4 clé CC (oranges). Ce qui est bizarre, c'est que si j'additionne la consommation de chaque clé, j'arrive à un total de 7,44 dollars et non pas 10,09 comme on pourrait s'y attendre ! WTF!? OK, il y a peut-être un temps de latence avant d'avoir "the full picture", mais tout ça est quand même assez opaque. 😤
Je poursuis avec OpenCode et leur modèle dédié (Zen ?), le seul qui veuille bien fonctionner. Je pars de presque rien (les Skills et les définitions des tâches linguistiques) et n'arrive à rien de potable. OpenCode semble à nouveau être en "YOLO mode" par defaut et je le trouve beaucoup moins intuitif que les autres (on ne peut pas faire référence à un fichier en faisant @fichier par exemple).
Lassé par les outils CLI, je retourne sur le Claude Web classique et parviens à générer et à peaufiner un script qui fonctionne pas si mal au bout de 5 itérations. L'utilisateur choisit un modèle de Groq et le script lance la révision (copy-editing) du texte et le sauvegarde en incluant dans le nom de fichier le nom du LLM utilisé. Il est ainsi plus facile de comparer les capacités des différents modèles en matière de correction-révision. En plus ça marche avec Word, SANS les Claude Skills, dont je commence à douter du bien fondé.
Je teste le plugin "llm-huggingface-plugin" dont je parlais hier et constate qu'il ne fonctionne pas correctement. Le plugin ne récupère aucune liste de modèles, la fonctionalité "register_commands" dans "hooks" est absente, et quand je tente de lancer llm -m hf/meta-llama/Llama-3.2-3B-Instruct "Write a haiku about coding", j'obtiens un message d'erreur. Il y a de l'espoir !
04-11-2025
J'ai rendu le dépôt Github de mon plugin "llm-hf" public : https://github.com/sebington/llm-hf. Je n'arrête pas de modifier le fichier README.md, il y a toujours quelque chose à changer.
Coup de théâtre. En me familiarisant avec l'interface de Github et en explorant la partie "Pull Requests" du projet LLM, je me rends compte que quelqu'un a déjà développé un plugin similaire il y a 3 mois. Cependant je constate que le projet semble un peu oublié et que pour l'instant Simon n'a pas jugé utile de l'ajouter à la liste officielle des plugins de LLM. Cela n'enlève rien à mes efforts et me conforte dans l’idée que le fait d'avoir un objectif bien défini est une des seules façons de progresser.
Suite à une remarque d'Olivier, j'ajoute la fonctionnalité "register_commands" dans "hooks". Pour ce faire je demande à Claude Code d'examiner le script d'un plugin similaire (llm-groq) et d'en extraire l'information pertinente. Cette fois je ne dépose pas le script dans le dossier du projet, je me contente de lui donner l'URL et CC va lui-même lire le script en ligne.
Maintenant, quand on tape llm plugins, on obtient (entre autres) :
[
{
"name": "llm-hf",
"hooks": [
"register_commands",
"register_models"
],
"version": "0.1.0"
}
]Et quand on tape llm hf, on obtient désormais :
Usage: llm hf [OPTIONS] COMMAND [ARGS]... Commands relating to the llm-hf pluginOptions:
-h, --help Show this message and exit.Commands:
models List all available Hugging Face models
refresh Refresh the list of available Hugging Face modelsClaude met systématiquement à jour CLAUDE.md et je lui demande de modifier README.md pour que la doc le soit également.
En revanche, grosse prise de tête avec la mise à jour des fichiers sur Github. Je ne maîtrise pas assez Git. Je fais tout en dépit du bon sens, parfois en ligne de commande, parfois avec VSCode, parfois en modifiant les fichiers directement sur Github. C'est le bordel et je perds un temps fou avec ça, ce qui est nul. Je sais que CC possède une fonctionnalité pour gérer Git mais je n'ai pas encore essayé de m'en servir. Ce serait peut-être plus fluide.
Last but not least, je constate que le modèle swiss-ai/Apertus-8B-Instruct-2509 ne fonctionne pas.
03-11-2025
Je dois modifier mon plugin (renommé "llm-hf") pour le faire fonctionner comme les autres plugins de LLM. Il y avait notamment un problème avec la gestion de la clé API (ou du "User Access Token") de Hugging Face. Stocké dans les variables d'environnement tout fonctionne bien. Mais les plugins de LLM proposent également un autre moyen de stocker la clé, notamment quand l'utilisateur tape llm keys set nom_du_plugin. Dans ce cas la clé est stockée dans un fichier JSON. Ce problème est maintenant réglé et tout semble bien fonctionner.
Je me familiarise avec la gestion d'un dépôt Github. J'apprends et mets en place les choses petit à petit. Par exemple : modification des infos sur le fichier README.md avec VSCode ou suppression des fichiers ajoutés à .gitignore avec :
git rm -r --cached .
git add .
git commit -m "Remove ignored files and update .gitignore"
git push02-11-2025
Simon Willison recommande cet article sur les multiples fonctionnalités de Claude Code. Le truc se veut assez complet, donc à garder sous le coude comme référence. Pratique.
Le MCP (Model Context Protocol) n'est peut-être pas (encore) la panacée. Dans cette vidéo, l'intervenant souligne que bien que le MCP vise à permettre à l’IA d’exécuter des tâches complexes, son efficacité réelle reste limitée par les contraintes fondamentales des LLM, notamment la taille de leur fenêtre contextuelle. À mesure que les informations fournies au LLM augmentent (lecture de documents, traitement de données, exécution de résultats d’outils), la fenêtre contextuelle du modèle se remplit rapidement, ce qui entraîne une dégradation des performances et un risque accru d’erreurs ou d'hallucinations. L'intervenant conclut en soulignant l’importance émergente du "context engineering" comme solution potentielle pour améliorer les systèmes agentiques et aider le MCP à tenir ses promesses.
J'essaie de réparer mon appli "proofreader" (version Groq) avec Gemini-CLI mais il ne s'en sort pas, alors je change de stratégie. Je lui demande de conserver toutes les fonctionnalités mais de tout "porter" en Python. Il s'exécute, et après quelques aller-retour, ça finit par fonctionner à peu près. En tous cas c'est beaucoup plus rapide qu'avec la version en React / TypeScript. Les changements sont bien visibles sur le fichier Word. Projet à poursuivre et à améliorer. Je fais un push vers Github avec VSCode.
Je retourne au projet consistant à créer un plugin "Hugging Face" pour l'outil LLM de Willison. J'avais commencé une ébauche avec Gemini-CLI mais je crois que je lui avais donné trop d'informations. J'avais en effet récupéré plusieurs "vrais" plugins sur Github et les avais inclus dans le projet comme exemples. Je lui avais aussi donné toute la doc de "LLM" sous la forme d'un gros PDF de 140 pages. Bonjour la consommation de tokens. Je réduis donc drastiquement la voilure et vire quasiment tout pour ne garder essentiellement que 3 fichiers :
1. le contenu de Developing a model plugin de la doc de LLM ;
2. le contenu de Inference Providers de Hugging Face (que j'ai sauvegardé en markdown directement depuis la version en ligne avec le bouton "copy page" en haut à droit, super pratique) ;
3. le fichier GEMINI.md
Je modifie GEMINI.md, dans lequel je réexplique clairement l'objectif du projet. Puis je le renomme en CLAUDE.md. J'installe Claude Code et le lance. Session incroyable pendant laquelle je sens les "super-pouvoirs" dont parlait NetworkChuck ! 🤩 Un peu fasciné, je regarde CC bosser et le guide quand il le faut. Au bout de 30 minutes j'ai un plugin fonctionnel. Je le teste et constate que la liste des modèles renvoyée n'est pas la bonne (trop courte et ne proposant que des "vieux" modèles). Je retrouve une fonction sensée récupérer la "bonne" liste de modèles HF (il y en a normalement 118) et la donne à CC, qui repart au quart de tour, intègre ce nouveau code, effectue des tests et met tout le projet à jour. Vingt minutes supplémentaires et c'est bouclé. J'obtiens un plugin installé et testé, avec toute la doc mise à jour, pratiquement prêt à être déployé sur Github. Un truc de ouf. Et cette fois ça ne me coûte que 43 cents ($0.4334).
01-11-2025
Je visionne cette vidéo. Le type est vraiment le youtubeur professionnel typique, à la fois insupportable et captivant. Sa vidéo au montage affûté comme un rasoir est un feu d'artifice des possibilités offertes par les nouveaux outils "CLI" comme Claude Code ou Gemini CLI. Mais on apprend des choses. Il montre par exemple comment créer des agents avec CC et qu'il est possible de faire bosser plusieurs IA sur un même projet, en même temps. Seul souci avec ce genre de démonstration : on ne sait pas de quel abonnement dispose ce youtubeur, qui est forcément un peu un influenceur. Il bénéficie peut-être de crédits gratuits de la part d'OpenAI ou d'Anthropic, vu la publicité qu'il leur fait.
Ai mis en ligne une copie de ce blog sur https://sebington.github.io/ avec l'outil Source Control de VSCode. L'ennui avec Github, c'est qu'à chaque fois il faut attendre un peu pour que les changements soient pris en compte, alors qu'en FTP classique, c'est instantané. Pour l'instant http://bytepacking.free.fr/ reste le plus fréquemment mis à jour. J'ai vu qu'il est normalement possible de sécuriser le site, mais la procédure est assez compliquée. Si free pouvait se bouger un peu sur ce sujet ce serait cool.
Je continue de travailler avec Gemini-CLI et améliore ma compréhension de l'outil. Ai retravaillé mon projet d'analyse de chaînes Youtube (renommé yt-trend). Les deux scripts ont été améliorés : "retrieve.py" est beaucoup plus rapide et "analyze.py" peut maintenant se connecter à une liste impressionante de modèles par le biais de 5 fournisseurs (Mistral, Groq, OpenRouter, Hugging Face et Claude). Pour OpenRouter, seuls les modèles gratuits sont affichés. J'essaie depuis peu de "pousser" ce qui fonctionne sur Github (en dépôt privé) pour m'y retrouver. J'adore Gemini-CLI, qui est vraiment super fluide. Je le préfère à Claude Code pour l'instant.
31-10-2025
Je suis un âne. Ce matin, la tête (relativement) reposée, je lis sur mon téléphone cet excellent billet de Simon Willison sur les "Claude Skills", dont j'avais reporté la lecture pour je ne sais quelle raison, et me rends compte qu'il répond précisément à tous mes questionnements. Il dit notamment :
"Something else I love about the design of skills is there is nothing at all preventing them from being used with other models. You can grab a skills folder right now, point Codex CLI or Gemini CLI at it and say “read pdf/SKILL.md and then create me a PDF describing this project” and it will work, despite those tools and models having no baked in knowledge of the skills system.",
ce qui me rassure, puisque c'est ce que je fais avec Gemini CLI depuis la sortie des Skills.
Nouvelle fonctionnalité sur le script de génération de cette page : la possibilité de créer un hyperlien en utilisant la syntaxe markdown, c'est à dire [lien]+(URL) (sans le signe +). La nouvelle fonction créée par Claude fait une fois de plus appel à un regex, qui repère la structure "crochets + parenthèses" et la transforme en lien hypertexte. L'utilisation de regex assure entre autre une génération ultra-rapide de la page.
Tentative de révision d'un texte en français bourré de maladresses et de fautes avec Claude Code. Je commence avec Sonnet, puis passe à Haiku pour économiser mes crédits. Dans un dossier je prépare un fichier README.md avec toutes les infos utiles pour CC (tâches, outils, environnement, etc.). Je mets aussi le contenu du dossier "docx/" des Claude Skills avec des instructions d'usage. Le résultat est décevant. Le texte n'a pas assez été retravaillé et de grossières erreurs persistent. Mon appli sur Google AI Studio fonctionne beaucoup mieux.
Total cost: $0.4781
Total duration (API): 3m 46s
Total duration (wall): 10m 14s
Total code changes: 360 lines added, 17 lines removed
Usage by model:
claude-haiku: 852 input, 8.9k output, 2.1m cache read, 62.0k cache write ($0.3280)
claude-sonnet: 818 input, 3.1k output, 120.8k cache read, 17.2k cache write ($0.1500)Même tentative avec Gemini-CLI qui décide de me lâcher juste après avoir analysé le projet. Message : API Error: code: 429, Resource exhausted. Please try again later.
Du coup je modifie mon appli dans Google AI Studio. L'utilisateur peut maintenant choisir entre 3 tâches linguistiques : "revision", "copy-editing" et proofreading". Le résultat n'est pas mal, Gemini propose 41 améliorations qui se justifient. En revanche il laisse une belle faute de grammaire : "...la ville a vécue une période sombre..." et des double ou triple espaces blancs. A faire : modifier cette nouvelle version de l'appli pour qu'elle fonctionne en local et qu'elle se connecte à un LLM puissant et rapide (Groq?).
NB : Ces efforts ont pour but de manipuler des textes en conservant leur format d'origine, l'indéboulonnable MS Word. Concernant les aspects purement linguistiques, un petit passage par ChatGPT avec le texte brut (.txt) donne de bien meilleurs résultats que tous les essais qui précèdent. C'est bien ce qui est rageant dans le métier de traducteur : l'encapsulation du texte nuit à son traitement.
Je soumets le même texte (.docx) aux versions web gratuites de ChatGPT et de Claude pour correction-révision. Tous deux récupèrent et corrigent le texte, mais aucun ne me livre un document Word : "lien mort" pour ChatGPT et "impossibilité technique" chez Claude. Olivier soumet le même texte à la version "Pro" de Claude et finit par obtenir un document Word révisé, mais fragile techniquement et linguistiquement.
Concernant les deux documents révisés issus des version gratuites de ChatGPT et de Claude, on peut les comparer à posteriori à l'original et pour chacun générer une version du document où l'on voit les modifications effectuées. A première vue ChatGPT semble avoir fait le meilleur travail, mais Claude n'est pas très loin derrière.
Statistiques
Claude : 209 révisions (86 insertions, 89 suppressions, 34 mises en forme)
ChatGPT : 308 révisions (131 insertions, 127 suppressions, 50 mises en forme)
30-10-2025
Je me rends compte que je confondais node.js, nvm et npm. 😏 ChatGPT me fait un petit résumé explicatif :
- Node.js is the core runtime that runs JavaScript on your system.
- NPM is automatically installed with Node.js and manages the dependencies your project needs.
- NVM sits above both — it manages which version of Node.js (and its bundled npm) you are using.Site de référence : https://nodejs.org/en/download.
Surprises, paradoxes et déceptions :
1. Je fais une session complète d'environ 15 min avec opencode et un modèle gratuit d'OpenRouter (MiniMax M2). Le résultat n'est pas foufou. A noter : opencode semble être en mode YOLO par défaut. Il prend toutes les décisions d'exécuter le code tout seul sans me demander mon avis !😮
2. J'enchaîne une session similaire avec Gemini-CLI et à peine a-t-il commencé qu'il cale :
⚡ Automatically switching from gemini-2.5-pro to gemini-2.5-flash for faster responses for the remainder of this session.
⚡ Possible reasons for this are that you have received multiple consecutive capacity errors or you have reached your daily gemini-2.5-pro quota limit
⚡ To increase your limits, upgrade to a Gemini Code Assist Standard or Enterprise plan with higher limits at https://goo.gle/set-up-gemini-code-assist
⚡ Or you can utilize a Gemini API Key. See: https://goo.gle/gemini-cli-docs-auth#gemini-api-key
⚡ You can switch authentication methods by typing /auth
✕ [API Error: Please submit a new query to continue with the Flash model.]alors que je ne l'ai pas du tout utilisé aujourd'hui. Où sont mes tokens gratuits ?? 🤔
3. J'achète 5 dollars (facturés 6) de crédits sur Claude Console pour pouvoir utiliser Claude Code (CC). Après avoir saisi mon numéro de carte bleue et mon adresse et tandis que je réfléchis encore à la somme que je veux mettre, le processus en ligne "décide" soudain de valider tout seul la transaction alors que je n'ai cliqué sur aucun bouton "Valider", WTF!! Méthode pour le moins "cavalière" de la part d'Anthropic je trouve.
Je lance ensuite ma première session avec CC. Elle se passe pas trop mal mais le résultat n'est pas au rendez-vous et je constate qu'elle m'a coûté $1.33 ! Je vérifie le modèle par défaut : il s'agit bien de Sonnet 4.5 comme je m'y attendais. Je suis néanmoins surpris après avoir entendu maintes et maintes fois Simon Willison dévoiler les sommes ridicules dépensées sur la génération de ses pélicans à bicyclette. Cela confirme ce dont personne ne semble parler dans les nombreuses vidéos sur YT concernant ces outils : ils sont un moyen de nous faire consommer du token à la pelle. Le généreux free-tiers de Gemini-CLI n'est pas si mal après tout.
Réflexion sur Claude Code et Gemini CLI (résumé d'un échange entre Olivier et moi)
Info importante concernant l'abonnement "PRO" de Claude : il ne permet pas d'utiliser l'API de Claude, contrairement l'abonnement "MAX". On ne peut donc pas lancer de scripts autonomes, mais on peut toujours faire appel à d'autres LLM pour cela.
Concernant les "Skills" pas mal de choses sont encore brumeuses dans mon esprit. Je me demande si CC y a accès par défaut ou s'il faut les lui donner en usage local, comme je le fais avec Gemini-CLI. Officiellement, pour bénéficier des "Skills", il faut les installer via un plugin dispo sur "anthropics/skills marketplace". Ensuite Claude les charge automatiquement quand il en a besoin. On peut aussi les installer "manuellement" en les ajoutant à ~/.claude/skills (pas très clair). Donc les lui donner en local reste possible, à condition de les avoir sous la main ou de savoir où les trouver.
Ceci dit les "Skills" permettent de faire toutes sortes de manipulations de fichiers (Word ou PDF par ex.) qui étaient impensables il y a 6 mois et qui sont super utiles dans mon boulot. Je me demande si l'utilisation que j'en ai faite dans Gemini-CLI est analogue à leur utilisation "native" dans Claude Web ou CC. En tous cas quand je regarde le détail des actions de Gemini-CLI lors d'une session, manifestement il s'en sert.
Olivier donne une précision importante : ce qui caractérise les Skills c'est la gestion du contexte : Claude lit le début de chaque fichier SKILL.md (champs "name" et "description") et ne lira la suite que si cela est nécessaire pour la tâche en cours. Cela permet d'économiser des tokens. Tandis qu'il est probable que Gemini-CLI intègre 100 % des infos contenues dans les Claude Skills dans son contexte, ce qui consomme davantage de tokens.
Je viens de faire une nouvelle session avec CC et j'ai maintenant dépensé 2 dollars sur 5 ! En gros on est à un dollar par session. Je vais essayer d'utiliser ce qui reste sur des tâches plus économes en API, en lançant des scripts autonomes par exemple.
29-10-2025
"Rainy day, dream away, let the sun take a holiday..." (Jimi Hendrix)
Je continue de tester Gemini-CLI et lui demande non pas de "construire un outil qui va faire", mais de "faire lui même" (je ne sais pas si ça a du sens), en l’occurrence réviser un texte au format Word (.docx) et produire une version révisée du document en mode "suivi des modifications". Je lui donne accès aux outils "Claude Skills". J'initialise le dossier avec uv pour qu'il puisse exécuter du Python. Et après l'avoir fait un /init, lui donne le prompt suivant :
Do a professional copy editing of @doc_en.docx. You can decide to use the tools provided in @tools/ or not. Output the result in a .docx file in tracked changes. The project has been uv initialized, you can use 'uv add ...' or 'uv run ...' if you need to execute Python. Reminder: Copy editing is a detailed linguistic and stylistic review focusing on grammar, syntax, punctuation, spelling, and consistency of tone, terminology, and formatting. It ensures clarity, precision, and adherence to stylistic or editorial standards without altering the substance of the content.
Les résultats ne sont pas très concluants. Gemini veut se servir de pandoc mais il bute sur l'installation malgré mon guidage. J'aurais dû lire le fichier GEMINI.md après sa création et installer pandoc au préalable. Il parvient tout de même à travailler sur le document mais soudain s'emballe quand il se lance dans une révision sans fin du xml interne au doc. Je l'arrête avant qu'il ne grille tous ses tokens et finis par le faire travailler sur le même document en TXT, ce qu'il fait, mais le résultat est décevant. Mon appli créée avec Google AI Studio fonctionne beaucoup mieux, sans être extraordinaire. A suivre.
Mon collègue JB me demande un service. Il voudrait pouvoir identifier la langue d'une collection de chaînes de caractères dans une base de données. Il voudrait utiliser l'API de DeepL, lui envoyer la chaîne de caractères et récupérer le code RFC 5646 de la langue ('en', 'fr', etc.). Après quelques tests, je me souviens que DeepL ne propose pas le breton dans sa bibliothèque de langues. Or JB a absolument besoin de pouvoir identifier du breton.
Je propose alors d'utiliser un LLM au lieu de DeepL. La demande de JB est un cas parfait de "Structured Outputs". On fait une requête bien précise au LLM et on filtre sa réponse pour ne récupérer que l'info dont on a besoin. Je consulte la doc de Groq et construis l'outil en quelques requêtes à Claude. Ça marche tout de suite. Le script boucle sur les données d'un fichier .tsv, envoie une chaîne de caractères à llama-3.3-70b-versatile sur l'API de Groq avec un prompt bien précis, récupère la langue et son code et stocke le tout dans un fichier JSON.
{
"row": 3,
"text": "[The Eisteddfod. A Great reunion]",
"language": "English",
"code": "en"
},
{
"row": 4,
"text": "[Lettre de Paul Diverrès à Yves Berthou]",
"language": "French",
"code": "fr"
}, etc.Après quelques essais nous changeons de modèle pour moonshotai/kimi-k2-instruct-0905, qui semble donner de meilleurs résultats. JB me demande aussi de simplifier et réduire le script à sa seule fonction : chaîne de caractères en entrée et code RFC 5646 en sortie, ce que Claude fait en quelques secondes. Je suis très fatigué et quasiment dans un état second, mais très content d'avoir pu travailler sur ce problème et d'avoir trouvé une solution viable. Je ne sais pas si JB, un peu réticent aux IA, va finir par utiliser cette solution mais au moins j'aurais mis en œuvre mes maigres compétences sur un "vrai projet", et cela m'emplit de joie.😄
Script : https://gist.github.com/sebington/382e2c6ebd43a28453c3c2541d4b241f
Je continue d'utiliser Linux Manjaro et parviens, à grand renfort de Claude, à localiser Freetube et à l'installer avec yay (yay -S freetube). Je constate toutefois que la recherche de "freetube" avec pacman (pacman -Ss freetube) ne renvoit rien. Claude me propose plusieurs solutions, par exemple de faire (pacman -Ss | grep -i freetube) ou même d'installer fzf (fuzzy search) pour le coupler à pacman, mais ça ne donne rien. C'est finalement la recherche directement avec yay (yay freetube), qui me permet de localiser freetube. Bref je me suis probablement trop focalisé sur pacman alors que yay semble être plus versatile et intuitif.
Découverte (re-découverte en fait) d'un merveilleux site qui propose toutes sorte de générateurs de bruits reproduisant au besoin toutes les ambiances souhaitées : https://mynoise.net/. Excellent.
28-10-2025
J'ai ajouté un formatage spécial pour les prompts dans le code de génération de cette page (rectangle aux bords arrondis). Je teste différentes polices et couleurs.
J'essaie de reproduire et de lancer un script en Python qui construit et teste un réseau de neurones (NN) très simple comportant une seule couche de 32 neurones. Ce NN génère des données aléatoires avec du bruit, puis analyse ces données pour retrouver la fonction "cachée" derrière. Source : https://www.youtube.com/watch?v=rdFjMb6dTJQ. Je pars de la vidéo et fais des captures d'écran du code, que je colle dans Claude et dans Mistral avec le prompt : OCR this image. Je récupère peu à peu tout le code que je colle dans un fichier.
Je demande à Ruff de vérifier le script reconstitué (uvx ruff check). Ruff détecte un petit problème (E702 Multiple statements on one line (semicolon)), mais cela ne devrait pas empêcher le script de fonctionner. J'ajoute un "uv inline script" en haut avec les bibliothèques pertinentes et lance le truc. UV met environ 15 secondes à télécharger et à installer les paquets. Étonnamment, Torch ne fait pas 1 Go comme d'habitude, mais plutôt autour de 100 Mo. Je me demande si uv détecte le fait que je n'ai pas de GPU et télécharge une version "light" (cpu-only) de Torch. Pure conjecture de ma part.
Ensuite tout va très vite (quelques secondes). Le script se lance et le NN s'entraîne sur 500 itérations ("epochs"). La sortie est exactement comme ce qui est montré dans la vidéo. Le NN prédit la courbe de x au carré et on voit les données d'entraînement en bleu et de test en marron. J'adore ce genre de petite expérience où l'on peut tester et mieux comprendre un des principes fondamentaux des réseaux de neurones et de l'intelligence artificielle. Script : https://gist.github.com/sebington/0ec87907ad0a079e6f59d941336d547c.
Ce soir, fatigué, je farfouille dans mes fichiers à la recherche du plus vieux morceau de code python que j'aie tapé sur un clavier. Je retrouve un script datant du 14 octobre 2020 où j'ai recopié le code de la vidéo suivante : https://www.youtube.com/watch?v=InUqeaOSPpA (Pytorch Torchtext Tutorial 2: Built in Datasets with Example). Qu'est-ce qui m'a fait choisir cette vidéo ? Pourquoi ne pas avoir commencé par le "Tutorial 1" ? Je crois que je trouvais ce gars qui tapait du code tout en semblant savoir ce qu'il faisait hyper cool. Dès le début je cherchais des choses en lien avec le langage et les mots : j'allais bientôt découvrir le NLP (Natural Language Processing) et toutes ses applications. Les LLM d'aujourd'hui viennent de là, du langage. « Au commencement était le Verbe, et le Verbe était avec Dieu, et le Verbe était Dieu. » — Premier verset de l'Évangile selon Jean.
27-10-2025
Je poursuis ma traduction "juridico-administrative", que je dois livrer demain. J'avais entendu dire que ChatGPT était d'une grande aide avec ce genre de texte. Je confirme ! Il connaît le droit international dans toutes ses nuances comme sa poche. C'est incroyable l'aide qu'il apporte.
Vu sur HackerNews, un site intéressant pour qui aime les cartes et les données GPS : https://geoutil.com/.
Concernant mon problème d'URL matching avec regex, j'interroge ChatGPT avec le prompt suivant :
Create a regex that will only match a URL, even if: 1. the URL is enclosed in brackets; 2. the URL is followed by a full stop; 3. the URL finishes with a slash "/"; 4. any combination of the above
ChatGPT me sort un regex assez long qui ne fonctionne pas mieux que le reste. Bon il faut avouer que mon prompt est un peu tordu dans sa formulation.
Olivier suggère pregrex, mais l'approche est assez ardue et le projet n'a pas été mis à jour depuis le 8 octobre 2022 (soit un mois avant la sortie de ChatGPT). J'essaie le regex qui est proposé dans la partie "Usage Example" de leur présentation, qui est sensé matcher une URL, mais c'est le même topo.
Je me rends sur https://lmarena.ai/?mode=direct et choisis claude-opus-4-1-20250805-thinking-16k avec un nouveau prompt :
Write a regex that will match any URL in a text, whether it is enclosed in brackets, finishes with a slash or a digit or is followed by a full stop.
J'obtiens 2 regex vraiment longs, sortes d'usines à gaz qui fonctionnent, mais butent sur les mêmes écueils (les points, les virgules).
Dernier essai sur le même site avec gpt-5-high (même prompt).
J'obtiens 2 regex un peu moins longs.
Je teste le premier et là bingo, ça marche ! Lancé dans Sublime Text, le truc matche toutes les URL de mon carnet de notes sans exceptions. Je crie victoire mais déchante aussi vite quand j'essaie d'intégrer le regex dans le code du script en Python qui génère cette page. Pour l'instant ça ne marche pas. Je me rends compte que le fait même d'afficher les différents regex essayés dans mes notes en TXT interfère avec la génération de la page (qui fait beaucoup appel à regex). Ça crée une sorte contamination. J'aurais dû y penser.
26-10-2025
Ce matin, je fais 42 km de VTT dans le vent et les embruns du côté de Ploudalmézeau. Salutaire pour me reposer les yeux et le cerveau.
Je travaille sur une traduction tout le reste du temps. Je réutilise mon outil d'alignement créé l'autre jour et me rends compte qu'il n'est pas assez convivial. Je demande à Claude de le modifier en laissant l'utilisateur choisir les langues et les fichiers et en le rendant un peu plus attractif visuellement avec rich. Le résultat est ici : https://github.com/sebington/txt-to-tmx-aligner.
Je continue de perfectionner le script en Python qui génère cette page HTML à partir de mes notes au format TXT. J'ajoute une fonction pour mettre la page en ligne en FTP. Je me rends aussi compte que certains liens générés par le script ne fonctionnent pas s'ils sont entre parenthèses ou suivis d'un point, ou s'ils finissent par "/".
La fonction de conversion d'URL en liens hypertextes fait appel à une expression régulière :
def linkify_urls(text):
url_pattern = r'(https?://[^\s<>]+)'
return re.sub(url_pattern, r'\1', text)Claude en a produit une version plus sophistiquée mais pas encore parfaite :
def linkify_urls(text):
url_pattern = r'(https?://[^\s<>]+?)(?=[.,;:!?)"\']?(?:\s|$|<))'
return re.sub(url_pattern, r'\1', text)Certains liens entre parenthèses fonctionnent tandis que d'autres non. Il va falloir investiguer.
A noter que mon script génère la page complète à chaque fois en une fraction de seconde. Cela me permet de corriger ou d'améliorer mes notes et de disposer d'un rendu instantané de l'ensemble.
25-10-2025
Je répare à nouveau mon Google AI Studio Proofreader. Je l'avais déjà fait hier et pensais qu'autosave était activé par défaut comme dans le reste des applis web de Google. J'étais dans l'erreur : il y a un bouton pour sauvegarder les changements apportés à l'appli, ce qui semble logique : pourquoi sauvegarder une appli si elle bugue ?
Je télécharge l'appli (fichier zippé) et fais bosser Gemini-CLI dessus. Je voudrais :
1. que l'appli fonctionne en local sur mon ordi
2. qu'elle se connecte à un autre modèle que Gemini via une API de mon choix (Groq par exemple)
Après quelques moments de débogage ça marche. Il faut que node (npm) soit installé. Je peux maintenant lancer l'appli en faisant npm run dev, ce qui démarre un serveur local accessible via http://localhost:3000/. L'appli se lance dans Firefox et fonctionne correctement avec un modèle de Groq. Le modèle utilisé est hardcodé dans un fichier nommé groqService.ts. Il s'agit de llama-3.3-70b-versatile. 😄
24-10-2025
Je demande à Gemini de réparer mon appli sur Google AI Studio dont l'interface graphique ne s'affiche pas et fais un essai avec un fichier complet. Mon "proofreader" détecte 130 changements, que je dois passer en revue un par un avant de l'accepter ou de le refuser. L'outil détecte un certain nombre de faux positifs quand il s'agit des majuscules ou minuscules. Je le modifie pour améliorer ce point et demande l'ajout d'un bouton pour accepter tous les changements d'un coup. Ça fonctionne. Le fichier en sortie est bien en mode "suivi des modifications" avec tous les changements clairement visibles.
Découverte du projet marimo : https://github.com/marimo-team/marimo. C'est une sorte de jupyter notebooks on steroids super prometteur. Par exemple, la sortie d'un bloc de code se met à jour en temps réel si on modifie le code. Et c'est du pur Python !
Première tentative de "git push" en ligne de commande (avec une image)
$ git clone https://github.com/repo_name/repo_name.github.io.git
$ cd repo_name.github.io/
$ git add images/nn.png
$ git commit -m "Add image to images folder"
$ git push origin main [provide Username and Password]Pour renommer un fichier
$ git mv index.html index_old.html
$ git commit -m "Rename index.html"
$ git push origin mainPour ne pas avoir à s'authentifier à chaque commit
$ git config --global credential.helper cache
# or store permanently (less secure)
$ git config --global credential.helper store23-10-2025
Simon Willison, probablement à la demande d'Anthropic, a supprimé de son Github les fichiers "Claude Skills" qu'il avait découverts et téléchargés avant l'annonce officielle d'Anthropic concernant ce nouveau service de Claude : https://simonwillison.net/2025/Oct/10/claude-skills/.
Nouvelle session Gemini CLI. Je lui demande d'utiliser les "Claude Skills" pour réviser un document Word et le livrer en mode suivi des modifications. J'oublie toujours d'activer le projet avec uv avant de commencer !
Prompt:
Do a professional revision (grammar, spelling, punctuation etc.) of @test.docx and output a .docx file in tracking mode where all the changes made are visible.
En parallèle je demande à Claude Sonnet 4.5 de faire la même chose dans l'interface web "classique".
Gemini bosse comme un dingue et grille son quota de tokens avant d'avoir terminé.
Claude crée une interface web inutile et ne parvient pas à sortir un document Word (erreur). Je le relance et il finit par me donner le résultat sous forme d'un fichier TXT avec les corrections (surtout l'orthographe) demandées.
Nouvelle tentative, dans Google AI Studio cette fois. Je crée une appli qui fonctionne du premier coup, prend un .docx, le révise, me montre les changements apportés et produit un document Word en mode suivi des modification. Le délire. Mais est-ce que ça marcherait avec un gros fichier ? Je retourne sur l'appli 3h plus tard et bizarrement le code est toujours là mais l'interface graphique ne se charge pas. Ecran noir.
Retour sur Manjaro Gnome. Je règle tous les problèmes rencontrés hier et savoure cette nouvelle distro qui est vraiment sympa.
Je suis un tuto de Simon Willison sur YT [5TdIxxBPUSI]. Pas très progressif et un peu fouilli, mais instructif. Je crée un dossier 'sqlite' et lance un jupyter notebook en faisant uv run --with jupyter jupyter lab où je tape les exemples de code. Tout fonctionne bien et je peux sauvegarder les sorties.
L'infatiguable Willison vient de mettre une nouvelle vidéo YT en ligne [GQvMLLrFPVI] dans laquelle il utilise Claude Code Web pour se fabriquer un outil à partir de 2 autres outils créés précédemment. On aperçoit au passage l'impressionnante collection d'outils dont il dispose et qui sont disponibles sur son github : https://tools.simonwillison.net.
22-10-2025
Avec Claude, je continue de modifier mon script de génération de HTML à partir de mes notes au format TXT (voir 19/10). Ça commence à devenir pas mal.
Je télécharge Linux Mint Cinnamon, l'installe sur une clé USB bootable avec Rufus et l'utilise pendant 30 minutes. Je trouve bien mes marques. Le terminal est imparamétrable une fois de plus et j'installe le terminal émulé "deepin" à la place. Plutôt pas mal.
21-10-2025
J'installe Manjaro Gnome pour voir. Pas mal de positif (look, rapidité, efficacité) mais certaines choses bizarres comme par exemple le fait que je n'arrive pas à lancer un outil installé dans uv et que je ne peux pas complètement désinstaller zsh, qui semble étroitement intégré à l'OS (dépendances). Le terminal pré-installé n'est pas paramétrable et j'en installe une autre version. En revanche, Nextcloud, Signal et OBS Studio fonctionnent à merveille.
Retour dans Ubuntu
Commande pour n'afficher que les modèles gratuits d'openrouter dans LLM:
llm models | grep ':free$'J'installe https://datasette.io/ avec uv
uv tool install datasette
llm models | grep ':free$'
llm -m openrouter/google/gemma-3-27b-it:free "What is Datasette?"
datasette "$(llm logs path)"cela donne l'accès à une interface web
INFO: Started server process [13667]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8001 (Press CTRL+C to quit)où on peut requêter la base de données de tout l'historique de LLM (prompts, modèles, réponses, etc.)
20-10-2025
Je visionne une vidéo YT [C44iCr6czAo] sur les dérives sécuritaires de Windows. Ça me donne envie de basculer sur Linux et d'y rester. Je télécharge 2 versions de Manjaro (KDE Plasma et Gnome) ainsi que CachyOS, que je teste tour à tour. Moi qui m'étais promis de me reposer les yeux ce soir, c'est raté.
19-10-2025
Je demande à Claude de me créer un script en Python (logbook-converter) qui convertit ce carnet de notes (au format .txt) en fichier HTML avec les prompts et les extraits de code reconnus et formattés. À suivre.
Je n'en finis pas de peaufiner le projet YouTube metadata (1. retrieve, 2. analyze). Le fichier "source" est une liste de chaines YT au format CSV (export de FreeTube), le fichier intermédiaire est un fichier JSON (channel_videos_2025.json) et la sortie finale peut se faire soit à l'écran (v2), soit écran + markdown (v2_md). Je finis par faire une vidéo.
Je continue d'essayer de construire un plugin Hugging Face pour Willison's LLM avec Gemini-CLI. C'est de la folie pure de s'attaquer à un truc pareil. Je vais néanmoins beaucoup plus loin qu'hier. Le plugin s'installe et récupère une liste de modèles. Cependant impossible de lancer une requête (Client error '404 Not Found').
18-10-2025
J'active Copilot dans VScode et le teste timidement. Copilot n'a pas compris que j'utilise uv et tente d'installer des librairies Python avec pip sur Ubuntu. Je l'arrête et y reviendrai dès que possible.
Suite à la découverte du nouveau HuggingChat il y a 2 jours, je me dis qu'il est probable que HF essaie de proposer quelque chose comme OpenRouter : une seule API donne accès à de nombreux modèles. Je pose la question à ChatGPT qui finit par me le confirmer après être allé lire la doc sur le site de Hugging Face.
Yes, Hugging Face is now offering a multi-provider inference capability via its Inference Providers framework that approximates the “one API, many models/providers” goal. The OpenAI-compatible API support is a particularly strong move, enabling you to reuse existing client libraries against HF’s routing system.
Convaincu par cette explication, je me dis qu'en théorie, je pourrais créer un plugin pour Simon Willison's LLM qui donnerait accès aux modèles de HF. Mais je me dis aussi que c'est peut-être un peu ambitieux de commencer par ça. Essayons déjà de voir si l'API de HF fonctionne comme prévu.
Je me rends sur https://huggingface.co/docs/inference-providers/ et finit par trouver un bout de code pour tester l'API. Il faut créer une clé spéciale (allowing inference providers). Le script fonctionne.
Je demande alors à Gemini-CLI d'incorporer HF aux 3 autres providers de mon script 2_analyze_gemini_v1.py (projet YouTube).
Prompt :
Use @test_hf.py to add Hugging Face as a new model provider in @2_analyze_gemini_v2.py.
Gemini-CLI le fait en 2 temps 3 mouvements. C'est totalement jouissif. Je lui demande la possibilité de pouvoir revenir à la liste des "providers" si je ne choisis pas de modèle tout de suite. On peut ainsi comparer le nombre de modèles proposés par chaque provider : Mistral = 68, Groq = 19, OpenRouter = 340 et Hugging Face = 115.
Je fais une vidéo sous Linux avec OBS Studio qui fonctionne enfin !
Je tente tout de même de créer le plugin HF avec Gemini-CLI, mais il ne veut même pas s'installer dans LLM.
16-10-2025
Je tente d'utiliser nextcloud en ligne de commande avec WSL pour tester la vitesse de synchronisation des fichiers:
mkdir nextcloud
sudo add-apt-repository ppa:nextcloud-devs/client
sudo apt update
sudo apt install nextcloud-clientMais c'est très galère : au lieu de spécifier quels dossiers on veut synchroniser, il faut exclure tous les dossiers que l'on ne veut PAS synchroniser
--exclude "SEB" --exclude "TAO" etc.Du coup je désinstalle tout.
Je génère de nouveaux scripts dans mon projet YouTube metadata :
- yt_metadata_csv.py (titre et upload date à partir de plusieurs chaines YT)
- retrieve_multiple_yt_video_titles.py (titre et upload date à partir de plusieurs videos)
Ce second script exporte le résultat du scraping de toutes mes URL de videos YT dans un fichier CSV (URL, Title, Upload date) que j'importe ensuite dans Google Drive. A noter que ce script n'utilise pas yt-dlp mais fait appel à requests et beautifulsoup4 et semble être plus rapide.
Le nouveau HuggingChat (https://huggingface.co/chat/) est une tuerie (116 modèles proposés).
Simon Willison reparle des "Claude Skills" sur son blog. Je suis certain que ce que j'ai fait avec Claude Skills et Gemini-CLI le 12/10 n'avait jamais été fait auparavant.
15-10-2025
L'alignement manuel des textes de ma collègue est décidément impossible avec memoQ. Obsédé par le côté récalcitrant de la chose, je demande à Claude de me créer un outil d'alignement.
I have two .txt files source (fr) and target (en) that I would like to align in order to obtain a translation memory (.tmx). Create a Python script that will scan the two .txt files line by line (this is important), retrieve all sentences and expressions pairs (source and target language) and store them methodically and chronologically in a dictionary, to be later exported as a .tmx file. Keep everything, even if source text is the same as target text but remove duplicate entries. Discard section numbering (e.g. 12.2.3.1) at the start of a line. Discard lines containing just one letter or only numbers. Keep all meaningful chains of characters. Segment at sentence level whenever possible. Attached are two extracts (source and target).
Ça marche ! One shot !😃 Le script génère un fichier TMX valide que j'importe dans memoQ sans problème. Dingue.
https://repomix.com/ is a powerful tool that packs your entire repository into a single, AI-friendly file.
https://www.kimi.com/en/ : sounds like another great LLM like Qwen and DeepSeek
14-10-2025
Je fais une vidéo sur la tentative d'alignement de fichiers .txt avec memoQ et sur la nouvelle approche avec Gemini CLI du 12/10.
Il faut que je m'intéresse aux "MCP server".
Une liste impressionnante : https://github.com/modelcontextprotocol/servers
Essayer celui-ci peut-être : https://github.com/vivekVells/mcp-pandoc
13-10-2025
Ce soir, je regarde deux vidéos passionnantes de la chaîne Underscore.
Dans la première, Grégoire Mialon et Clémentine Fourrier de Hugging Face expliquent comment les LLM sont évalués. Je visite ensuite le site de Clémentine Fourrier dont j'adore le côté minimaliste avec en bas ce lien sur une manière minimaliste et pérenne de concevoir un blog.
La seconde vidéo est consacrée à un outil très original de géolocalisation d'images développé par Nicolas Dufour (voir https://nicolas-dufour.github.io/plonk).
Je fais des essais de mise en ligne de ce carnet sur http://bytepacking.free.fr/. Du bon vieux html. Pour mettre la page en ligne, j'utilise un outil primitif fourni par free : http://ftpperso.free.fr/index.pl.
Liens du jour :
Pense-bête uv (Olivier) : https://mathspp.com/blog/uv-cheatsheet
Sortie de NanoChat d'Andrej Karphaty : https://github.com/karpathy/nanochat
Sauvegarder une session Gemini-CLI en markdown doit être possible : https://gist.github.com/simonw/12c7b072e8e21ef1e040fb3b69c1da28
12-10-2025
Je me penche sur les outils de Claude (Claude Skills) pour manipuler les fichiers et fais un essai avec le répertoire dédié à Word (.docx). La "boite à outil" étant assez complexe, je décide de faire bosser Gemini CLI dessus (avec uv pour exécuter les scripts en Python). Après tout ces outils ont été conçus pour être pilotés par un LLM. L'objectif est de remplacer du texte FR par du texte EN dans un document Word (.docx) en le copiant d'un fichier à l'autre, sans altérer la structure (images) du fichier cible.
Je fais 3 tentatives. Une session sur Windows, mal configurée, produit un fichier illisible. Mais les deux autres (sur Ubuntu) fonctionnent. Avec 2 fichiers très simples constitués de 4 paragraphes de texte et de 2 images en FR (et la même chose en EN), je demande à Gemini CLI de trouver un moyen de remplacer le texte du fichier en français par le texte du fichier en anglais, sans altérer la mise en page et les images.
Using the available tools in this project, devise a strategy to replace the text from @input-fr.docx by the text from @input-en.docx, keeping the layout and integrity of the target document.
Il s'exécute et produit un fichier cible où le texte en français a été remplacé par le texte en anglais. Mais comment être absolument certain qu'il n'a pas simplement copié le fichier source dans son intégralité ? Je fais une deuxième tentative plus ambitieuse : je ne laisse dans le répertoire de travail que le fichier Word FR, auquel j'ajoute le texte en anglais au format TXT. Je demande à Gemini CLI la même chose, c'est à dire de remplacer le texte en FR par le texte en EN, mais cette fois à partir du fichier TXT.
@input-fr.docx is a .docx of a short text in French with photos. @en-text.txt is a replacement text in English for the docx file. Use the tools provided here to edit @input-fr.docx and replace the text it contains by the text in @en-text.txt while keeping the photos.
Sans surprise, il n'y arrive pas. Je lui demande alors de faire une comparaison LINGUISTIQUE des contenus avant commencer l'opération et ça marche !
Use a linguistic approach and run a similarity search to check that the meaning of each paragraph in English of @en-text.txt corresponds approximately to the paragraph in French. If so then copy it over the French in the .docx file.
Il compare les textes, établit des correspondances entre les paragraphes et remplace le texte FR par le texte EN au bons endroits, sans toucher aux images ! 😃 Mais ce n'est qu'un début et les fichiers utilisés sont hyper simples.
[EDIT] : dans les manipulations décrites ici, il n'est pas question de créer des scripts autonomes réutilisables plus tard, mais bien de laisser Gemini-CLI orchestrer les opérations et répondre aux demandes de l'utilisateur en temps réel grâce à l'écosystème du projet reposant sur la partie docx des Claude Skills.
A faire : complexifier les fichiers .docx (ajouter par ex. numérotation, gras, italiques)
11-10-2025
Je visionne à nouveau 10+ tools to use ai in the terminal et prends des notes. Le gars aurait mieux fait d'intituler sa vidéo "Demo of Simon Willison's LLM" ! Sur le même sujet, il y a aussi Become a command-line superhero with Simon Willison's LLM tool, au titre plus approprié.
Je découvre un post de Simon Willison concernant les "Claude Skills", des outils de manipulation de fichiers de Claude que Simon a "hacké" à demi-mots : "This is a really sophisticated set of tools for document manipulation, and I love that Anthropic have made those visible - presumably deliberately - to users of Claude who know how to ask for them." (https://simonwillison.net/2025/Oct/10/claude-skills/).
09-10-2025
Le problème de l'alignement automatique des textes pour le projet de ma collègue semble insoluble. Même si les résultats d'hier soir sont encourageants. Je tente de passer tout en .txt et compare dans notepad++. Même la numérotation des sections n'est pas fiable !😫
08-10-2025
Tentative de génération d'un outil d'alignement "sémantique" multilingue de textes avec ChatGPT, Claude (OpenRouter/Mistral) puis Gemini CLI. L'idée est de faire appel à un modèle de génération d'embeddings et à un autre LLM classique pour aligner des paires de phrases dans deux documents parallèles, l'un étant la traduction de l'autre.
De plus en plus je rencontre les limites des accès API "Free Tier". Est-ce voulu ? Bizarrerie : l'accès OpenRouter fonctionne pour mon script "analyze YouTube metadata" mais pas avec "aligner OpenRouter". Je pose la question à ChatGPT qui me donne une explication vaseuse et un patch qui ne marche pas.
Claude me donne la bonne explication un peu plus tard : l'accès à OpenRouter va vite "dans le rouge" parce que mon script, par définition, fait de multiples requêtes au modèle pour tenter d'établir des ponts entre chaque phrase de ma paire de documents ! L'explication de ChatGPT était complètement à côté de la plaque.
Je refile le bébé à Gemini CLI et le fait bosser sur plusieurs déclinaisons du script (il améliore la fonction embeddings) avec OpenRouter seul, puis avec Ollama (embeddings) et OpenRouter (LLM), puis comme le free tier d'OpenRouter est grillé, avec "ollama seul" (embeddinggemma et gemma3) et ça marche enfin sans erreurs ! Le résultat de l'alignement est stocké dans un fichier JSON. Le script est quand même assez long : 500+ lignes de code, et je ne sais pas ce que vaut l'alignement.
Je change mon mot de passe Google sur mon PC via le navigateur et je reçois une notification sur mon smartphone Xiaomi alors que j'avais supprimé le compte Google du téléphone. Ça laisse songeur.
07-10-2025
Je fais le gros ménage dans mes scripts (YT metadata). Instructif. Inutile de garder des vieux scripts. Perte de temps.
06-10-2025
Vidéo pour Olivier (YT metadata) très mal préparée et décevante. Mais ça me fait avancer.
05-10-2025
Un effet particulièrement délétère de l'arrivée de l'IA dans les entreprises de services, c'est l'assomption par le client que la prestation est désormais exécutable en 2-3 clics de souris, que le devis qui lui est envoyé est surcoté et n'est pas le reflet du travail réellement effectué.
autoencoder mnist plan
1. after training do not run the test set
2. ask user to input a square image of a handwritten digit
3. normalize the image (size, color, bit depth) so that is complies with the train set
4. submit the image to the model
5. display the model's best guess
Ai retesté llamafile sous Windows (qwen3 et gemma3) et je trouve la génération plus rapide.
Ai testé Google Jules sur autoencoder hébergé sur Github. Bluffant.
Ai installé Gemini CLI sur Powershell, puis modifié autoencoder avec. Super bluffant.
04-10-2025
Installation de la version beta 25.10 d'Ubuntu. Elle propose un nouveau terminal par défaut (ptyxis) difficile à paramétrer. Je finis par réinstaller le gnome-terminal.
J'installe Nextcloud et constate que la mise à jour des fichiers est à nouveau rapide. La DSI a peut-être résolu le problème de lenteur. Ce faisant j'oublie de sauvegarder les logs de Gemini CLI ! 😫
Je visite le site de Fabrice Bellard et c'est parti pour un petit voyage technologique passionnant. Je télécharge son projet /tsac/ et le teste avec un mp3 de piano (renommé toto.mp3) dans powershell :
./tsac c toto.mp3 toto.tsacLe fichier passe de 4707 Ko à 101 Ko !!
Je peut ensuite reconvertir ce fichier hyper-compressé en WAV :
./tsac d toto.tsac toto.wavLe fichier .wav fait 26 Mo. Je ne détecte pas de perte de qualité sonore.
Je demande des explications à Claude concernant le rôle du Transformer (voir "Ultra-low bitrate audio compression") et il me répond :
The Transformer model acts as a learned compressor on top of the DAC encoding. It takes the discrete codes produced by the DAC encoder and finds patterns and redundancies in these codes. The DAC does the heavy lifting of converting audio to a compact form, but the Transformer notices that even within this compact form, there are patterns (temporal dependencies, repetitions, predictable sequences) that can be exploited for additional compression.
EDIT : Sur ce sujet, voir aussi https://openzl.org/.
Autre projet de Fabrice Bellard : https://textsynth.com/, un serveur de LLM !
On peut maintenant convertir un livre entier en audio avec kokoro.
03-10-2025
Grosse fatigue. Je continue de prépare la présentation Youtube Métadata mais la gestion des multiples versions des scripts m'épuise. Il faut changer de méthode. Je tente une vidéo mais m'empêtre dans des explications sans fin.
02-10-2025
Nouveau script (Claude) pour visualiser les conversations ChatGPT avec leur date de création convertie en date standard.
Quand on y réfléchit, le chemin qu'on prend pour arriver à un résultat peut être très alambiqué, il y a toutes les fausses pistes, les prompts qui ne donnent rien, les scripts ou les prompts que l'on réutilise, que l'on passe à une IA, puis à une autre, sans résultat tout de suite utilisable, ou parfois juste un peu à coté de la plaque.
Découverte (grâce à mon collègue JB) de Stéphane Mallat. Coup de foudre. J'écoute tout ce que je peux trouver sur lui : https://www.radiofrance.fr/franceculture/podcasts/la-science-cqfd/stephane-mallat-la-palme-d-ondes-1077850.
01-10-2025
J'essaie de retracer le workflow de mon projet "YouTube metadata retrieval and analysis". Je cherche les premières conversations en espérant que ce soit bien sur Claude ou ChatGPT. Ça semble être le cas. Très difficile de s'y retrouver.
Pour ChatGPT, j'exporte mes données et ouvre ensuite chat.html, dans lequel je peux faire une recherche par mots-clés. Normalement sur la version en ligne je devrais avoir un outil de recherche comme dans Claude, mais il n'apparaît pas sur ma version de ChatGPT, ce qui est bizarre. En plus de chat.html, ChatGTP propose un autre fichier (conversations.json) dans lequel les dates sont au "Unix epoch format (seconds since January 1, 1970, UTC)".
Pour Claude version web, je peux utiliser leur outil de recherche, mais ça cherche uniquement les TITRES de conversations, pas leur contenu. Je fais donc également un export de mes données et j'obtiens entre autres un fichier conversations.json que j'ouvre avec Sublime Text et que je peux parser manuellement. Ce n'est pas très pratique alors je demande à Claude de me faire un script qui génère une page HTML comme pour ChatGPT. Ça marche nickel après quelques itérations.
J'arrive à reconstituer un historique rudimentaire :
2024-10-30 ChatGPT : YouTube metadata (last modif. 2025-01-26)
2024-12-09 Claude : Aggregate YouTube Channel Titles from JSON
2024-12-11 Claude : YouTube Channel Video Scraper
2025-09-28 ChatGPT : Combine scripts and classify trends
2025-09-28 Claude : YouTube video download error
2025-09-30 Gemini CLI session
30-09-2025
How to download and open a .parquet file in ipython repl using uv (ubuntu):
uv init parquet
cd parquet
uv add ipython pandas pyarrow
wget https://huggingface.co/datasets/ylecun/mnist/resolve/main/mnist/test-00000-of-00001.parquet -O mnist-test.parquet
ipython
import pandas as pd
df = pd.read_parquet('mnist-test.parquet')
print(df.head())
print(df.columns)
print(df.describe())Je demande à Claude de créer un convertisseur .epub vers .azw3, ce qu'il fait (epub_to_azw3.py). Le script a besoin que Calibre soit installé pour fonctionner (décevant).
Je visionne avec intérêt une vidéo YT de Jodie Burchell, "Build a Semantic Book Recommender" [Q7mS1VHm3Yw]. Voix très agréable et explications limpides.
J'installe Opencode (curl -fsSL https://opencode.ai/install | bash). Petit essai rapide, mais à priori Opencode est beaucoup moins intuitif et efficace que Gemini CLI.
Nouvelle session incroyable sur Gemini CLI pour mon projet "YouTube metadata retrieval and analysis". Après 2h de 'pilotage', j'obtiens 2 scripts qui tiennent la route. Incroyable ce que ça marche bien. Le second script permet entre autres de lister tous les modèles proposés par l'API d'un fournisseur. Chez Mistral j'ai cru voir 2 modèles faisant de l'OCR. J'utilise aussi OpenRouter qui propose plusieurs modèles gratuits parmi les dizaines proposés via leur API.
29-09-2025
Papillonnage
Le taux de transfert en écriture sur ma carte microSD branchée avec un lecteur de carte USB3 est assez médiocre (env. 60 Mo/sec). Pas de changement si je formate la carte en NTFS au lieu de ExFAT. Le taux de transfert avec un disque SSD et son adaptateur SATA-USB3 est bien meilleur : env. 350 Mo/sec en lecture comme en écriture.
Un traducteur explique comment il utilise des LLM pour travailler.
Sortie de Claude Sonnet 4.5 : https://www.anthropic.com/news/claude-sonnet-4-5.
Je mets à jour LLM (uv tool upgrade llm) et constate que tous les plugins ont disparu ! Sur le sujet voir : https://github.com/simonw/llm/issues/575. Il semblerait que Simon n'ait pas corrigé le problème.
Je modifie un script "autoencoder with MNIST dataset" avec Claude Sonnet 4.5 et ça fonctionne.
28-09-2025
Projet "YouTube metadata analysis". J'essaie de combiner plusieurs scripts en un seul, avec un fichier .csv en entrée contenant une liste de chaînes YouTube (ChatGPT : "Combine scripts and classify trends") mais résultats inconsistants d'un run à l'autre. Faut-il avoir recours au RAG ?
27-09-2025
Visionnage de vidéo YT :
- 10+ tools to use ai in the terminal
- LLMs on the Edge of the Scaling Laws (Jodie Burchell)
- LLMs for Devs: Model Selection, Hallucinations, Agents, AGI (Jodie Burchell)
Article très intéressant de David Crawshaw sur la manière de programmer avec des LLM.
26-09-2025
Refresher sur llamacpp, qui ne veut plus se lancer depuis son répertoire en faisant 'llama-cli -m modele.gguf' comme avant. Solution :
# Download the latest llamacpp precompiled binaries
# Unzip and stick everything in (for example) $HOME/llamacpp/
# Add the build dir to your PATH
echo 'export PATH="$HOME/llamacpp/:$PATH"' >> ~/.bashrc
source ~/.bashrc
# Launch a model
llama-cli -m path_to/model.ggufEDIT : manip ci-dessus inutile si on fait ./llama-cli -m modele.gguf dans le répertoire où llamacpp est installé (j'avais oublié)
Retour à la vidéo de Willison sur son outil LLM. Vers 28'35", je fais une copie d'écran de son exemple de script en bash qui résume les thèmes des commentaires d'un sujet de Hacker News et je demande à Claude de transcrire le texte de l'image, ce qu'il fait sans aucune erreur. Je colle le code dans un fichier (hn_summarizer.sh), auquel je donne les droits d'exécution (cmod +x hn_summarizer.sh), puis je remplace 'haiku' par 'groq/openai/gpt-oss-20b', mon modèle par défaut dans llm.
Ensuite je choisis un sujet au hasard dans Hacker News et clique sur le lien pour afficher les commentaires (ex. https://news.ycombinator.com/item?id=45384653). Je copie le numéro d'id (45384653) et lance le script de Willison en faisant ./hn_summarizer.sh 45384653. J'obtiens un résumé des thèmes abordés. Avec la version gratuite de mon modèle (fenêtre contextuelle limitée) je ne peux pas choisir de sujets qui ont trop de commentaires (30 maxi je dirais). Mais je peux changer de modèle et mettre par exemple openrouter/meta-llama/llama-3.3-70b-instruct:free.
Post de Simon sur le sujet : https://til.simonwillison.net/llms/claude-hacker-news-themes
25-09-2025
Essais de conversion et de reconstruction d'un document PDF de 60 pages en Word. Ma collègue Catherine convertit le doc avec Acrobat Pro mais nous savons d'expérience que la mise en page est très "fragile", surtout si on doit modifier le document. J'essaie avec différentes IA (Gemini, Mistral, Claude, ChatGPT) de passer du texte brut copié à partir du PDF à du markdown propre et structuré. C'est ChatGPT qui donne le meilleur résultat, au moins pour le début du document.
Prompt :
This text is a raw copy from a PDF document. Reformat it as readable markdown. Do not alter its content. Do not summarize. Do not translate.
Je demande ensuite à Claude de créer un script qui convertit le markdown généré par ChatGPT en Word et ça marche. Mon intuition me dit que le fichier Word ainsi généré est beaucoup plus robuste que le fichier issu de la conversion avec Acrobat. Cependant cette méthode induit encore de trop nombreuses approximations pour être réellement fiable.
Je me replonge dans Willison's LLM. J'installe plusieurs plugins : llm-cmd, llm-command-r, llm-ollama, llm-groq, llm-openrouter, llm-mistral. Je crée un compte sur OpenRouter. Je visionne la vidéo de Mark Needham sur LLM.
Commandes intéressantes :
llm 'Who is Simon Willison?' > output.txt(écrit le résultat de la requête dans le fichier output.txt)
cat /etc/*-release | llm -s "Tell me about my operating system"(pipe le résultat de la commande Bash, y ajoute un prompt et lance la requête)
24-09-2025
Tentation de refiler aux IA (sans trop y croire) des trucs jugés difficiles ou infaisables. Je donne à Gemini (interface web) un texte brut sans mise en forme issu d'un copier-coller sauvage d'un PDF avec le prompt suivant :
Produis une version fidèle et restructurée en markdown de ce document en prenant soin de faire apparaître les titres de section et les paragraphes. Ne le traduis pas.
Gemini s'exécute, puis je ne sais pas ce qui se passe, il bugue et je perds tout.
Je télécharge une appli web "gpx-map-filter" générée il y a quelques jours avec Google AI Studio. Cette appli me permet de retrouver les fichiers GPX correspondant à une zone prédéfinie sur une carte ("bounding box"). Je demande à Gemini CLI de faire fonctionner l'appli en local. Gemini CLI me dit qu'il faut créer une clé API sur Google Cloud. Je lui réponds que je n'en ai pas. Il me donne alors une solution sans avoir recours à une clé API ! Il faut installer node et lancer un serveur en tapant npn run dev. Ça fonctionne.
20-09-2025
Fichiers GPX : le retour de ChatGPT. Après m'être perdu avec Claude et ses scripts interminables, une simple requête à ChatGPT produit un script d'une soixantaine de lignes qui fait le taf sans essayer de centraliser tous les points des GPX dans un dataframe, ce que je m'obstine à faire depuis des mois. On peut vraiment être aveuglé par ce qu'on croit être une bonne idée.
Prompt :
I want to clean up many gpx files from various devices and format. I have made a python script that parses gpx files, stores all latitude, longitude, elevation and timestamps points into a dataframe, removes duplicate entries and for each date (yyymmdd) outputs clean gpx files. This kinda works for some files, however many exported files have points in the wrong chronological order, making them useless. Can you think of a better approach to solve this problem?
Une fois de plus je constate que complexité ne rime pas forcément avec efficacité.
18-09-2025
Je reconstitue partiellement la démarche du projet "docx-images" avec les 3 sessions de Gemini CLI que je regroupe dans un seul fichier texte.
Je me replonge dans l'idée de produire des fichiers GPX "propres". Je perfectionne un outil en ligne de commande généré sur Claude. Le script finit par être assez long (1000+ lignes de code) et n'est pas foufou. Certaines fonctions du menu ne fonctionnent pas correctement. Je génère d'autres scripts avec Claude jusqu'à en perdre la tête. C'est le problème de ces outils. Il faut être hyper-organisé sinon on peut se noyer dans les scripts.
16-09-2025
Je poursuis mon projet de retirer/remettre les images avec des documents Word. J'utilise le script d'hier soir (qui fonctionne avec des documents .odt) comme base pour Gemini CLI et lui demande d'en faire une version qui fonctionne avec des fichiers Word. Cette fois ça marche après seulement 2-3 itérations (docx_image_manager.py). Mais le plus fort c'est que j'essaie ensuite avec le fichier d'un client contenant 423 images et ça fonctionne ! Je n'en reviens pas. Il faudrait que j'arrive à retracer toute la démarche. Je crois qu'au début je suis parti d'un script généré par Claude.
15-09-2025
J'installe Gemini CLI dans WSL npm install -g @google/gemini-cli. Pour se loguer avec son compte Google dans WSL, je dois taper gemini nobrowser=TRUE.
Je fais travailler Gemini CLI sur un problème assez ardu. Créer un script qui prend un fichier DOCX avec des images en entrée, retire toutes les images et génère un fichier sans images (qui ainsi sera beaucoup plus léger et pourra être importé dans notre CAT tool). Une fois le fichier traduit un second script remet toutes les images à leur juste place. Pour l'instant mon script n°1 parvient à retirer les images, mais le n°2 n'arrive pas à les remettre. Gemini CLI a bossé comme un dingue pour y arriver, sans succès. C'était fascinant comme session. Je lui ai dit d'utiliser uv (uv run script.py) et il l'a fait. Il s'est arrêté 2-3 fois et je lui ai dit "continue" et il a continué !
Ma première approche consiste à lui demander de créer des "placeholders" numérotés "image1.jpg", "image2.jpg", etc., ce qu'il fait, mais je me rends compte que ce n'est pas la bonne méthode. Je lui demande alors d'extraire le "squelette XML" du docx. Il parvient à retirer les images sans toucher au code XML. Ça donne un fichier Word sans images avec des sortes de cadres vides à la place, comme quand il manque une image sur un site internet. Je crois que passer par le XML qui est constitutif des fichiers .docx est la bonne voie, mais Gemini a vraiment beaucoup de mal à gérer le truc. Impression que la manière dont un fichier Word est encodé est un vrai cauchemar, même pour une IA !
Mon beau-frère Olivier suggère d'essayer la même manip avec le format Libre Office (.odt). Le soir je reprends tout depuis le début avec un fichier ODT contenant du texte et des images. Je demande à Gemini CLI de créer 2 scripts : un qui enlève les images et génère le doc sans images et un second script qui prend le doc sans images et les remet. J'atteins bientôt la limite du modèle pro et n'ai d'autre choix que de continuer avec gemini-2.5-flash mais ça finit par fonctionner. Chose surprenante, les scripts générés ne sont pas si longs que ça (beaucoup moins que pour Word). Je regroupe les 2 scripts en un seul avec un menu basique : 1. retirer les images, 2. remettre les images. Gemini-2.5-flash semble bien marcher pour ce genre de petites modifs (odt_image_manager.py).
Je me rends compte que les outils comme Gemini CLI et Claude Code sont l'aboutissement de toutes les avancées dont on entend parler depuis la sortie de ChatGPT : chain-of-thought prompting, RAG, fonction calling, tool use, augmentation de la taille de la fenêtre contextelle, agents autonomes, MCP... Tout ça enfin mis en oeuvre de manière cohérente. Je demande à ChatGPT s'il est d'accord avec mon constat et il me répond comme d'habitude en me caressant dans le sens du poil :
Tu touches un point très juste 👍 : des outils comme Gemini CLI et Claude Code incarnent une sorte de "synthèse appliquée" de toutes les briques d’innovation accumulées dans le domaine des LLM depuis fin 2022. Au début, on avait "juste" ChatGPT comme assistant conversationnel. Puis, étape par étape, des concepts et technologies se sont empilés pour transformer les LLM en véritables systèmes intelligents, interactifs et spécialisés.
14-09-2025
Oneliner pour lancer un Jupyter notebook sans se prendre la tête
Installer uv, puis faire :
uv run --with jupyter jupyter labMême chose avec ipython :
uv run --with ipython ipython------
Je regarde ce que devient LLM, l'outil de Simon Willison. Je ne peux m'empêcher de penser que Claude Code et Gemini CLI s'en sont grandement inspirés.
------
Pyodide est un outil épatant qui permet d'exécuter du code Python dans un navigateur.
13-09-2025
Je m'amuse avec Gemini CLI depuis 2 jours. L'outil est vraiment impressionnant. Ce qui est dingue c'est que Gemini CLI en mode gratuit permet de vraiment travailler (60 requests/min and 1,000 requests/day). Je lui donne l'accès à un répertoire contenant plusieurs scripts en Python plus ou moins récents permettant de manipuler les fichiers GPX et lui demande de les analyser. Il identifie tout de suite les plus aboutis et peut les améliorer tout en les testant avec de vraies données. On peut lui demander n'importe quoi, il code, il réfléchit, il exécute en Bash, la totale. Et il possède une fenêtre contextuelle d'un million de tokens. Selon Gemini, le script le plus abouti de mon répertoire est un script écrit par Claude.
02-09-2025
Groq toujours au top pour transcrire les fichiers audio, à condition de réduire leur taille au préalable avec ffmpeg (fichier < 40 Mo). Pour obtenir une transcription "diarisée" (identification des interlocuteurs), je passe la transcription brute obtenue avec Groq à Claude avec le prompt suivant :
Le texte ci-joint est la transcription brute d'un entretien entre 2 interlocuteurs. Peux-tu améliorer cette transcription en veillant à séparer les prises de paroles et en prenant soin de retirer tous les tics de langage, répétitions inutiles, etc., tout restant fidèle aux propos tenus? Le texte final devra être fluide et agréable à lire."
Le résultat est bluffant. Le modèle parvient à identifier les changements d'intervenants et à découper leur prises de paroles respectives à partir de cette simple transcription écrite sans repères d'aucune sorte.
01-09-2025
Retour au boulot et reconnexion progressive à l'IA après la pause estivale. Nous avons reçu une demande de transcription d'enregistrements et je me replonge sans transition dans Whisper et autres joyeusetés en matière de speech-to-text. Je teste Voxtral (voxtral-mini-latest), le modèle speech-to-text de Mistral. Ça marche, mais la transcription est tronquée car le modèle est payant. Groq semble toujours fonctionner. Ils ont retiré un modèle (distil-whisper) de leur liste.
🤖